딥러닝 라이브러리인 keras 입문을 시작하겠습니다.
이 글은 딥러닝에 대한 기초적인 이론 이해와 컨셉에 대한 개념을 잡았다는 전제 하에 쓰도록 하겠습니다.
코드 위주로 진행하려고 합니다.
코드 위주로 하면서 설명을 곁들이도록 하겠습니다.
하나의 인강과 책을 참고했습니다. (포스팅 제일 하단에 링크 걸었습니다 :)
1) 모델 만들기
우선 기초적인 그림을 보겠습니다.

딥러닝을 공부하시는 분이라면 너무나 익숙한 뉴럴네트워크의 그림입니다.
이제 간단한 레이어들을 구성해보겠습니다.

케라스는 사실 layer를 쌓는데 굉장히 직관적으로 코딩을 할 수 있게 되어 있습니다. 그래서 어느정도 익숙해졌다면 pytorch 나 tensorflow 로 모델을 구성하는 것이 맞습니다. keras 의 경우, 모델을 만드는데 자유도가 어느정도 제한이 있기 때문입니다. 고로, keras로 여러 문제에 맞게 코딩할 수 있다면 pytorch / tensorflow 2.0 으로 넘어가길 권유합니다 :)
위에 그림은 색깔을 기준으로 layer라고 보시면 됩니다. layer 가 3개고, 각 layer 마다 유닛의 갯수(동그라미) 다 다릅니다.

(케라스 설치는 따로 다루지 않습니다)
위 그림의 모델을 케라스로 만들어 보겠습니다.
먼저 Sequential 을 model 이라는 이름으로 선언합니다. 일단 형태는 불러온다고 보면 될거 같습니다. 하나의 레이어만 있다고 보시면 됩니다. 하지만 하나 있는 레이어의 유닛은 아직 정해지지 않습니다. 변수를 초기화 했다고 보시면 될 거 같습니다.
그 다음 층을 하나 추가해주면서 첫 번째 레이어(input layer) 유닛 갯수를 정해줍니다. 히든 레이어가 하나 더해지는데 이 때 input layer의 유닛도 같이 넣습니다. 위에선 activation function 을 sigmoid로 합니다.
그 다음 레이어를 또 하나 추가해줍니다. output layer 에 유닛이 하나입니다.
제대로 짰는지 확인해보겠습니다.

mode.summary()
을 통해 layer 정보를 확인할 수 있습니다. input layer 는 따로 dense 로 표기되지 않습니다. add를 한 layer 부터 나오는데요.
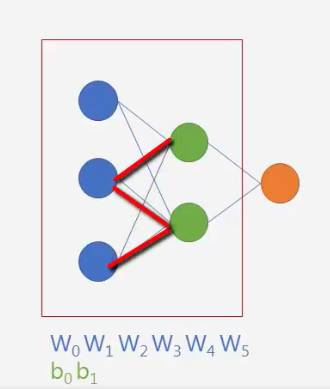
그림을 보시면 input layer의 unit 3개와 hidden layer 의 Unit 2개가 연결된 선의 갯수(=weight 의 갯수는 6개) 입니다.

거기에 hidden layer 의 Unit 2개가 각각 bias 이므로 dense_1에서 총 parameter 는 8개가 됩니다.
dense_2(=output layer) 는 연결된 선이 2개 output layer unit이 1개 이므로 3개의 parameter가 됩니다.
param 의 갯수가 왜 그렇게 나오는지 이해가 되셨나요?
자, 이제 뼈대는 완성되었습니다. 살을 붙여야 되는데요.
만들어진 모델이 어떤 방향으로 학습할지 설정해줘야 합니다.

모델을 학습시키기 이전에, compile 메소드를 통해서 학습 방식에 대한 환경설정을 해야 합니다. 다음의 세 개의 인자를 입력으로 받습니다.
- optimizer:. rmsprp나 adagrad와 같은 기존의 정규화기에 대한 문자열 식별자 또는 Optimizer 클래스의 인스턴스를 사용할 수 있습니다.
- loss function: 모델이 최적화에 사용되는 목적 함수입니다. categorical_crossentropy 또는 mse와 같은 기존의 손실 함수의 문자열 식별자 또는 목적 함수를 사용할 수 있습니다.
- metric: 분류 문제에 대해서는 metrics=['accuracy']로 설정합니다. 기준은 문자열 식별자 또는 사용자 정의 기준 함수를 사용할 수 있습니다.
2) IMDB 예제
5만개의 리뷰 데이터셋인 IMDB를 이용해서 모델링을 해보겠습니다.
이 데이터셋은 훈련 데이터 2만 5,000개와 테스트 데이터 2만5,000개로 나뉘어 있고 50%는 부정, 50%는 긍정 리뷰로 구성되어 있습니다. 이 예제는 Colab에서 진행합니다.
런타임 유형은 GPU 로 변경해주시구요. (사실 로컬 CPU로 해도 될만한 예제이긴합니다.)
num_words = 10000 매개변수는 훈련 데이터에서 가장 자주 나타나는 단어 1만개만 사용하겠다는 의미입니다. 드문 단어는 무시합니다. 자연어처리에서는 단어의 빈도수와 문서(여기에서는 리뷰가 하나의 문서)들에서의 빈도수가 중요합니다. 모든 단어를 벡터화 시키면 연산량이 커지기 때문이죠.

각 리뷰는 단어 인덱스의 리스트입니다. train_labels 와 test_labels 부정을 나타내는 0과 긍정을 나타내는 1의 리스트입니다.
아래 리스트 컴프리헨션은 각 리뷰가 1만개를 넘지 않는다는 것을 보여줍니다.

신경망에 숫자 리스트를 주입할 수는 없습니다. 텐서로 바꿔야 되는데요.
위 코드의 함수는 원핫 벡터로 변환하는 함수입니다.
사실, 케라스는 정수 인코딩 된 결과로부터 원-핫 인코딩을 수행하는 to_categorical()를 지원합니다. (이는 나중에 다른 포스팅에서 보여드리겠습니다 :)
그리고 정답 레이블은 astype을 통해 쉽게 벡터로 바꿀 수 있습니다.
이제, 신경망에 주입할 데이터가 준비되었습니다.
모델의 뼈대를 만들어보겠습니다.

히든레이어는 2개이며 input layer의 유닛은 1만개입니다. (각 리뷰별로 단어가 1만개이니깐요!)
summary 를 통해 많은 weight 와 bias 들이 있음이 보입니다.
Dense 층에 전달한 매개변수(16)은 은닉 유닛의 개수입니다. 하나의 은닉 유닛은 층이 나타내는 표현 공간에서 하나의 차원이 됩니다. relu 활성화 함수를 사용한 Dense 층을 다음 텐서 연산을 연결하여 구현한 것입니다.
output = relu(dot(W,input) +b)
16개의 은닉 유닛이 있다는 것은 가중치 행렬 W의 크기가 (input_dimension, 16)이라는 뜻입니다. 입력 데이터와 W를 점곱하면 입력 데이터가 16차원으로 표현된 공간으로 투영됩니다.(그리고 편향 벡터 b를 더하고 relu 연산을 적용합니다.) 표현 공간의 차원을 '신경망이 내재된 표현을 학습할 때 가질 수 있는 자유도'로 이해할 수 있습니다. 은닉 유닛을 신경망이 더욱 복잡한 표현을 학습할 수 있지만 계산 비용이 커지고 원하지 않는 패턴을 학습할 수도 있습니다.
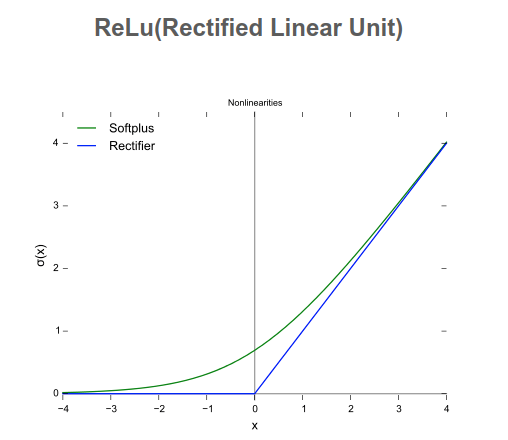
마지막 층은 확률입니다. 어떤 샘플이 타깃 '1'일 가능성이 높다는 것은 그 리뷰가 긍정일 가능성이 높다는 것을 의미합니다. relu는 음수를 0으로 만드는 함수입니다.
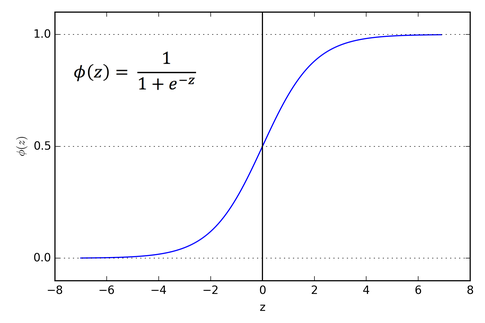
시그모이드는 임의의 값을 [0,1] 사이로 압축하므로 출력 값을 확률처럼 해석할 수 있습니다.

train 셋에서 validation 셋을 나눠줍니다. 그냥 인덱싱하면 됩니다!

compile 메서드를 통해 학습의 방향을 잡아주시면 됩니다. 영화 리뷰를 이진분류하는 문제이고 신경망의 출력이 확률이기 때문에 로스 함수는 binary_crossentropy로 정했습니다.
모델을 512개의 샘플씩 미니 배치를 만들어 20번의 에포크 동안 훈련시킵니다.

model.fit() 메서드는 History 객체를 반환합니다. 이 객체는 훈련하는 동안 발생한 모든 정보를 담고 있는 딕셔너리인 history 속성을 가지고 있습니다.

matplotlib 을 이용하여 훈련과 검증 데이터에 대한 손실과 정확도를 그려봤습니다.

그래프를 통해 훈련 손실이 에포크마다 감소하고 훈련 정확도는 에포크마다 증가합니다. 경사 하강법 최적화를 때 반복마다 최소화되는 것이 손실이므로 기대했던 대로입니다. 검증 손실과 정확도는 이와 같지 않습니다. 특정 에포크에서 그래프가 역전되는 것처럼 보입니다. 오버피팅이 일어났다고 할 수 있습니다.
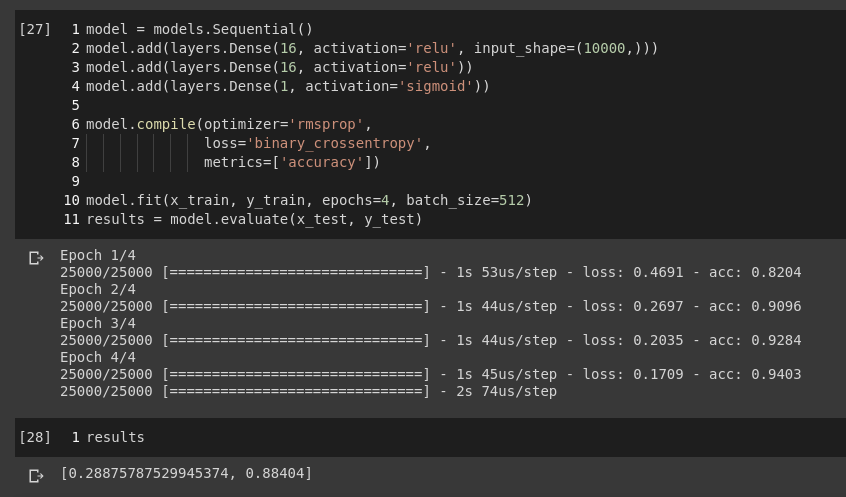
에포크를 줄여서 88%의 정확도를 얻었습니다. 과대 적합을 피하기 위해서는 에포크를 줄여서 할 필요도 있습니다.
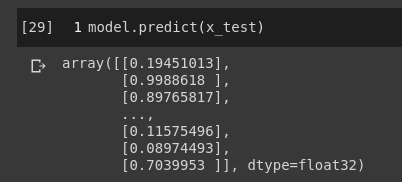
predict 메서드를 사용하여 어떤 리뷰가 긍정일지 확률로 예측해 보는것으로 이번 포스팅을 마치겠습니다.
--------참고-------------------------------
1) '케라스, 인공지능의 공용어 완전 정복'
creApple - “Creative Application Era”
www.creapple.com
2) 케라스 창시자에게 배우는 딥러닝
http://www.yes24.com/Product/Goods/65050162
케라스 창시자에게 배우는 딥러닝
단어 하나, 코드 한 줄 버릴 것이 없다!창시자의 철학까지 담은 딥러닝 입문서케라스 창시자이자 구글 딥러닝 연구원인 저자는 ‘인공 지능의 민주화’를 강조한다. 이 책 역시 많은 사람에게 딥러닝을 전달하는 또 다른 방법이며, 딥러닝 이면의 개념과 구현을 가능하면 쉽게 이해할 수 있게 하는 데 중점을 두었다. 1부에서는 딥러닝, 신경망,...
www.yes24.com