이번 시간부터 파이썬으로 프로그래밍 알고리즘을 다뤄보려고 합니다.
제가 워낙 약한 부분이라서 공부하면서 정리하고자 하니 첨언이나 조언 있으시면 언제든지 댓글 주시면 감사하겠습니다 :)
지금부터 쓰는 이 글을
프로그래머스에서 하는 '어서와! 자료구조와 알고리즘은 처음이지?' 강의를 듣고
문제를 풀면서 이에 대한 내용들을 정리를 위한 글입니다.
오늘은 선형 배열에 다뤄보려고 합니다.
1) Linked Array
선형 배열은 데이터들이 선 (line) 처럼 일렬로 늘어선 형태를 말합니다. 보통 프로그래밍에서 배열 (array) 이라고 하면 같은 종류의 데이터가 줄지어 늘어서 있는 것을 뜻하는데요, Python 에서는 서로 다른 종류의 데이터 또한 줄세울 수 있는 리스트 (list) 라는 데이터형이 있습니다.
이 강의에서는 같은 종류의 데이터가 줄지어 늘어서 있는 배열을 이용하려 합니다. 앞으로 배열 (array) 이라는 말과 리스트 (list) 라는 말이 자주 등장할 겁니다만, 우선은 같은 것이라고 생각해도 좋지만, 개념적인 구조, 즉 데이터를 늘어놓은 모양새를 말할 때는 배열 (array), Python 의 데이터형을 가리킬 때에는 리스트 (list) 라는 용어를 사용하겠습니다.
또한, 연결 리스트 (linked list) 라는 용어가 등장하게 되는데, 이것과는 구별되어야 합니다. 그것은 그때 가서 다시 얘기하기로 해요.

리스트에선 인덱싱이 가능합니다. 인덱싱 번호를 이용해서 value를 찾는 것인데요. 인덱스는 0부터 시작됩니다.
O(1)
시간복잡도라고 들어보셨나요? 몇 가지가 있는데, 우선 위와 같이 '빅오원' 이 있으면 순식간에 (빠르게) 할 수 있는 일을 의미합니다. 리스트의 길이와 무관하게 상수 시간 동안 시간이 소요됩니다.

위는 시간 복잡도의 표입니다. 정리를 아주 잘해주셨습니다. 이쁘게 정리해주셔서 감사드립니다. :)
위 시간 복잡도는 아래로 갈수록 오래 걸린다고 보시면 됩니다. 즉, 빅오원은 제일 시간이 짧게 소요됨을 의미합니다.
빅오원에 해당되는 두 가지 연산을 소개하겠습니다.
1) 리스트 끝에다가 원소 추가하기 - append

리스트의 끝에 (=리스트이름[-1]) 원소가 추가시켜주는 메서드입니다.
2) 끝에 있는 원소를 꺼내기 - pop
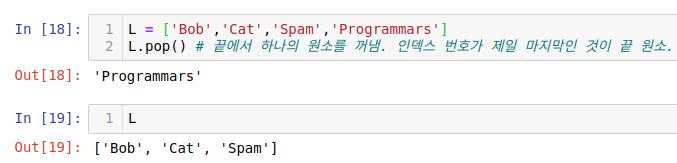
리스트 끝에 있는 원소를 꺼내주는 연산입니다.
두 가지 연산 모두 메서드가 적용되고 그 결과가 기존 리스트에 반영되는 것을 확인할 수 있습니다.
O(n)
선형 시간만큼 시간이 소요되는 메서드를 소개하겠습니다. 리스트의 길이가 길면 오래 걸리는 연산입니다.
리스트의 길이에 비례 (선형 시간) 합니다.
3) 원소 삽입 - insert
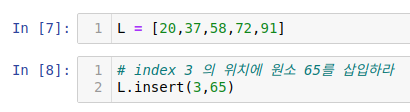
3번 인덱스 위치를 찾고 맨 뒤에 수를 한 칸 뒤의 인덱스로 밀어줘야 합니다. 그 뒤에 기존 3번 째 인덱스를 다시 4번째로 밀어줍니다. 마지막으로 65가 3번째 인덱스가 들어갑니다. 대략 4번 정도?의 연산이 일어나네요. 리스트 크기가 하나 증가하는 거지만 append를 할 때보다 좀 더 많은 일이 내부에서 일어납니다. 그래서 앞에 연산자들보다 시간복잡도가 큰 거 같습니다.
4) 원소 삭제 - del
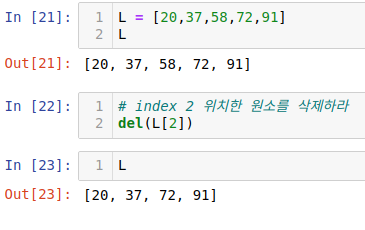
인덱스2 에 위치한 원소를 삭제하고 인덱스3에 위치한 원소가 2로 땡겨지고, 4번째도 3번째로, 5번째는 4번째로 한칸 당겨지면서 리스트의 길이는 하나 줄어들게 됩니다.
+) del 과 pop 둘 중에 뭐가 더 빠를까?
del 을 쓰는 것과 pop 을 쓰는 것은 결과적으로는 비슷해보이지만 pop 이 좀 더 연산의 행위가 간결하기에 시간이 짧은거라는 생각을 했었습니다.
그런데...

여러 숫자를 넣어서 중간 위치를 적용해서 del 과 pop 을 적용해봤는데 거진 다 del 이 빨랐다...
pop() 과 del 은 지우고자 하는 리스트의 인덱스를 받아서 지우는 방식입니다. 두 개의 차이는 pop()은 지워진 인덱스의 값을 반환하지만 del 은 반환하지 않습니다. 이 차이로 인해 미세하지만 del이 pop() 보다 수행속도가 빠릅니다. 또한 remove()와 동일하게 pop() 과 del은 특정 인덱스를 삭제한 다음, 리스트를 재조정합니다.
그렇다.
연산 속도: del > pop
인 것이다.
근데 이게 중요한가? 싶지만, 나중에 이러한 사소한 메서드 선택의 차이로 대용량을 처리할때 시간 차이를 줄여서 효율적으로 코드가 반영이 될 수도 있지 않을까 싶다. 일단 한 번 봐두고 넘어가자.
5) 원소 탐색 - index
중요한 연산자니깐 크게 했다. O(1) 의 시간 복잡도를 가진 연산이다.

연산자에 대한 5가지는 이 정도로 정리하겠습니다. 연습문제를 풀어보겠습니다.
**연습문제1**
리스트 L 과 정수 x 가 인자로 주어질 때, 리스트 내의 올바른 위치에 x 를 삽입하여 그 결과 리스트를 반환하는 함수 solution 을 완성하세요.
인자로 주어지는 리스트 L 은 정수 원소들로 이루어져 있으며 크기에 따라 (오름차순으로) 정렬되어 있다고 가정합니다.
예를 들어, L = [20, 37, 58, 72, 91] 이고 x = 65 인 경우, 올바른 리턴 값은 [20, 37, 58, 65, 72, 91] 입니다.
힌트: 순환문을 이용하여 올바른 위치를 결정하고 insert() 메서드를 이용하여 삽입하는 것이 한 가지 방법입니다.
주의: 리스트 내에 존재하는 모든 원소들보다 작거나 모든 원소들보다 큰 정수가 주어지는 경우에 대해서도 올바르게 처리해야 합니다.
1) 방법1 - 메서드 범벅
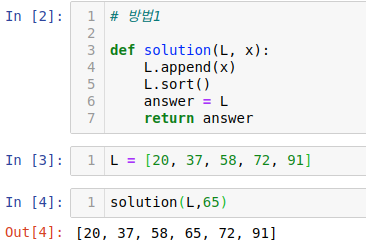
메서드 범벅으로 풀어보았다. 근데 메서드 범벅으로 저렇게 푸는건 좋은 거 같지는 않아 보여서 힌트에 있는 방법으로 해보았다.

힌트대로 해보려고 했는데 저럴 경우 문제가 x 가 리스트 안에 원소들보다 모두 클 경우 반영이 안된다!
처음에 저 상태로 제출했더니 테이트 케이스에서 66점 맞았다. 그래서 원소가 첫 번째, 마지막에 반영될 때 고려해서 추가 케이스를 추가했더니 저런 오류를 깨달았다.
여튼 첫 번째와 마지막 경우를 if 로 추가해주자!
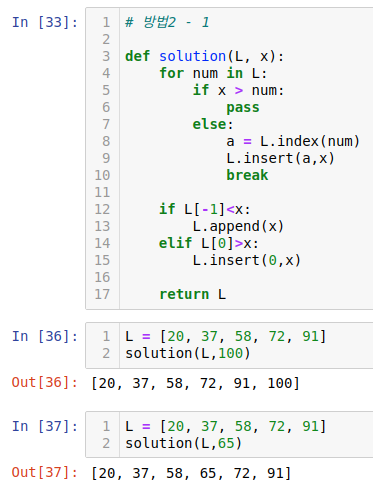
통과했다! 하지만...
다른 분들의 코드 리뷰를 보았는데 피드백들을 보았는데...
아래와 같은 질의응답이 있었다.
Q. for문에서 L의 원소값 중 x값보다 클때 그 원소값을 찾아서 insert로 넣어주는 방법으로 구현했는데, 속도가 조금 느립니다. index함수를 호출해서 그런건가요..?
A.맞습니다. 그것을 매 원소 l 에 대하여 반복할 이유가 전혀 없지요. 순환문이 인덱스를 기록하면서 반복할 수 있도록 바꾸어 보세요.
어떤 분의 코드 리뷰인데 다른 분 리뷰에서도 순환만 안에 인덱스 메서드를 쓰는 것이 속도를 조금 느리게 한다고 한다.
나도 순환문 안에 index 메서드를 썼는데...ㅠㅠ
피드백을 내 코드에도 반영해서 index 를 다르게 찾아보려고 해보았다.
+) enumerate 를 사용해보기로 했다!

enumerate 메서드를 사용하면 위와 같이 길이만큼 인덱스를 달아주는 효과를 볼 수 있다.
언패킹을 해주는거 같은데? enumerate 쓰고나서는 순환문에서 두 개의 원소를 꺼내주도록 해줘야한다.(위 코드참고)

index 메서드 말고 enumerate 를 이용해서 해당 인덱스의 위치를 찾아보았다.
이게 더 속도가 빠르지 않을까라는 생각이 든다. index는 리스트를 한 번 훏어야 되는데 enumerate 할 때는 그냥 조건 맞으면
바로 그 해당 인덱스위치가 바로 같이 뽑아냈으니깐 바로 insert 에 넣으면 되니깐!
정확히 내 생각이 맞는지는 모르겠다.
여튼 위 문제는 저정도로 정리하려고 한다.
저 문제 하나 풀고 든 생각들을 정리하자면
1) for 문 안에서 index 메서드 쓰는 건 비효율적인 것 같다. 리스트 메서드를 2번 조사해야 되서 그렇다. 1번만 리스트를 조사해서 해결할 수 있다면 굳이 2번을 할 필요는 없다. 이를 위한 방안 중 하나는 enumerate 가 아닐까 싶다.
2) 크기 비교를 할 때는 타겟 원소가 기존 리스트 원소들 무엇보다도 클 수도 있고 작을 수도 있다. 이럴 경우도 고려해서 조건을 걸어주자!
3) 메서드 범벅으로 문제를 푸는 것은 시간복잡도나 이런 면에서 좋지 않은 것 같다.
정도이다.
자, 다음 문제. 하나 더 있습니다!
**연습문제2**
인자로 주어지는 리스트 L 내에서, 또한 인자로 주어지는 원소 x 가 발견되는 모든 인덱스를 구하여 이 인덱스들로 이루어진 리스트를 반환하는 함수 solution 을 완성하세요.
리스트 L 은 정수들로 이루어져 있고 그 순서는 임의로 부여되어 있다고 가정하며, 동일한 원소가 반복하여 들어 있을 수 있습니다. 이 안에 정수 x 가 존재하면 그것들을 모두 발견하여 해당 인덱스들을 리스트로 만들어 반환하고, 만약 존재하지 않으면 하나의 원소로 이루어진 리스트 [-1] 를 반환하는 함수를 완성하세요.
예를 들어, L = [64, 72, 83, 72, 54] 이고 x = 72 인 경우의 올바른 리턴 값은 [1, 3] 입니다.
또 다른 예를 들어, L = [64, 72, 83, 72, 54] 이고 x = 83 인 경우의 올바른 리턴 값은 [2] 입니다.
마지막으로 또 다른 예를 들어, L = [64, 72, 83, 72, 54] 이고 x = 49 인 경우의 올바른 리턴 값은 [-1] 입니다.
힌트 1: 리스트의 index() 메서드와 리스트 슬라이싱을 활용하는 것이 한 가지 방법이 됩니다. 리스트 슬라이싱은 아래와 같이 동작합니다.
L = [6, 2, 8, 7, 3] 인 경우
L[1:3] = [2, 8]
L[2:] = [8, 7, 3]
L[:3] = [6, 2, 8]
힌트 2: 리스트의 index() 메서드는, 인자로 주어지는 원소가 리스트 내에 존재하지 않을 때 ValueError 를 일으킵니다. 이것을 try ... except 로 처리해도 되고, if x in L 과 같은 조건문으로 특정 원소가 리스트 내에 존재하는지를 판단해도 됩니다.
일단 힌트 안보고 그냥 한 번 해봤습니다.

elif 부분이 좀 걸렸습니다. 그래서 다른 분들 풀이를 보니 저랑 유사하게 푼 분들 중에 컴프리헨션으로 하신 분이 있었는데요.
그전에, elif 부분은 그냥 else 로 처리해보았습니다.
이제 좀 괜찮네요

헌데 이 코드를 더 깔끔하게 하신 분이 계셨으니...

보통 for 문이랑 if 문 같이 쓸 때는 컴프리헨션으로 해도 좋은데 마침 그렇게 하신 분이 계셨습니다.
제일 파이썬 스러운 코드네요!
저도 항상 for + if 구조면 컴프리헨션으로 짜보려고 하는데 잘 안되네요 ㅠㅠ
오늘 문제 풀이는 여기까지 입니다!
--참고--
https://brownbears.tistory.com/452
[Python] 리스트 slice, pop, del 성능 비교 및 사용방법
slice, pop, del 사용방법 remove() remove()는 지우고자 하는 인덱스가 아닌, 값을 입력하는 방식입니다. 만약 지우고자 하는 값이 리스트 내에 2개 이상이 있다면 순서상 가장 앞에 있는 값을 지우게 됩니다. 해..
brownbears.tistory.com
https://daimhada.tistory.com/56
Python 내장 함수의 시간 복잡도
Python 컨테이너 메소드의 시간 복잡도(time complexity)는 어떻게 될까? 알고리즘을 풀면서 컨테이너를 조작하기 위해 기본 메소드들을 많이 활용하게 되었고, 메소드의 시간 복잡도가 궁금해졌다. 경우에 따라서..
daimhada.tistory.com
'Python_programming > 알고리즘' 카테고리의 다른 글
| 파이썬 알고리즘 기초 - 스택(Stack) (0) | 2020.01.31 |
|---|---|
| 파이썬 알고리즘 기초 - 큐(Queue) (0) | 2020.01.31 |
| 파이썬 알고리즘 기초 - 하노이의 탑 (재귀 알고리즘) (2) | 2020.01.26 |
| 파이썬 알고리즘 기초 - 이진 탐색(binary search) (0) | 2020.01.24 |



