지난 시간에 했던 공공데이터 분석의 2단계입니다.
시각화 작업을 할겁니다.
우선, 시각화 작업하기 전에 pandas, seaborn 위주로 시작화를 하긴할겁니다. 헌데, 이 때 알아두셔야 하는 것은
그래프를 여러 가지 형태로 그린다는 데 초점을 맞추면 좋을 것 같습니다. 세부적인 그래프의 모든 옵션은
일일히 직접 입력해보면서 그래프의 변화를 관찰하면서 만드는 게 좋다고 생각합니다.
만약, 보고서 또는 공모전 용도로 한다면 디자인에 대한 생각을 해야겠지만 이 프로젝트 개인적인 토이 프로젝트 느낌이며 공부하는 용도이기에 조금은 라이트하게 하려고 합니다. 또, 그래프 쓸 때마다 매번 시프트,탭을 눌러서 한 번 확인하고 하는 것이 좋습니다. 기본적으로 x y 축에 데이터프레임의 컬럼을 타입에 맞게 넣고, hue 옵션이 있으면 이를 넣어주고 subplot 형태로 여러 개 나오도록 구성도 해주고 하는 것이 전반적인 그래프 그릴 때의 느낌입니다.
두서없는 서론이 길었습니다. 시작해보겠습니다.

지난 시간에 했던 작업을 이어서 하는 거니깐 1단계를 보고 오거나 해당 포스팅 하단에 있는 깃허브 링크에서 ipynb 를 다운받은 뒤에 run 시키고 그 뒤부터 작업하시면 될 것 같습니다. [ 물론 지금 작업한 것도 따로 올립니다 :) ]
matplotlib 폰트 조정도 따로 포스팅 했으니 그 부분 참고해서 봐주시면 됩니다.
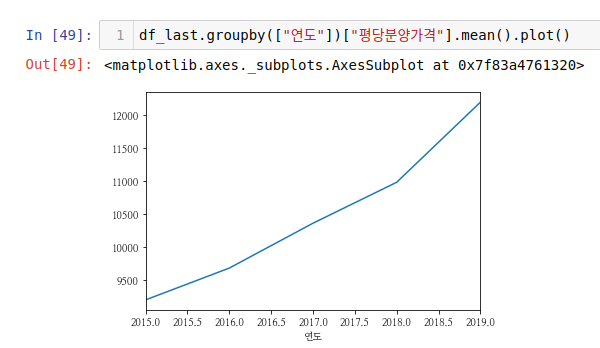
pandas 로 그래프를 그릴 때는 항상 집계함수로 형태를 만들어준 뒤에 함수 메서드를 그려줘야 합니다. 위에서 지역명을 인덱스로 두고 평당분양가격을 컬럼으로 두는 시리즈 형태의 데이터가 집계되었습니다. 이를 sort 시켜준뒤에 내림차순으로 해줍니다.
그리고 해당 데이터의 .plot() 을 해주면 기본적으로 꺽은 선 그래프를 그립니다.
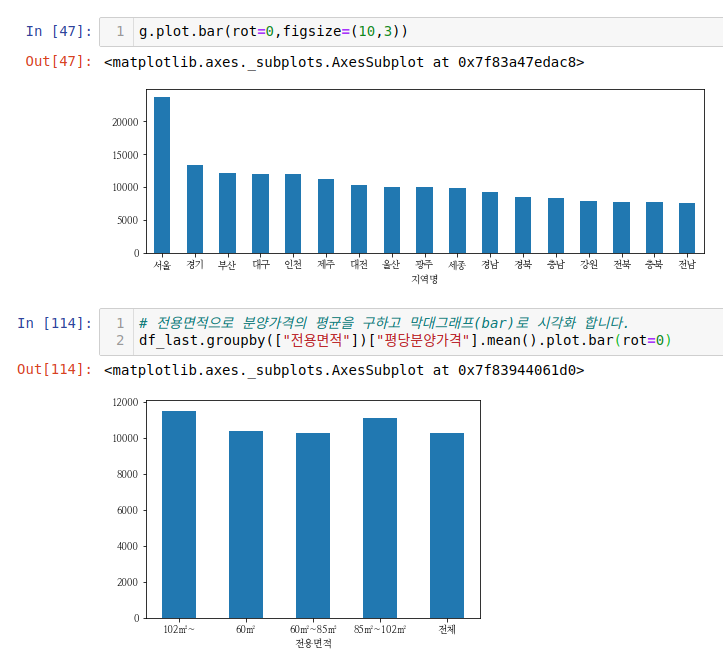
.plot.bar 처럼 plot 다음에 원하는 타입의 그래프를 저겅주면 그에 맞게 그래프를 그려줍니다. (In [114] 기준) 객체화를 일일히 하지 않고 집계 함수로 데이터 프레임을 변환한 뒤에 바로 .plot.bar 를 해주셔도 됩니다.
정리하자면, pandas 로 그래프를 그릴 때는
집계 함수 사용해서 데이터 프레임을 만들고, plot 메서드 적용한다
로 먼저, 생각하시면 됩니다.
위 그래프를 보고 알 수 있는 것은 해마다 평당분양가격이 오른다는 사실과 평당분양가는 서울,경기,부산 순이다라는 것입니다.
# boxplot
박스 플롯은 기초통계학을 공부하셨다면 한 번 쯤은 보셨을 겁니다. 위에서 알아야할 용어들은
- 백분위 수 : 데이터를 백등분 한 것
- 사분위 수 : 데이터를 4등분 한 것
- 중위수 : 데이터의 정 가운데 순위에 해당하는 값.(관측치의 절반은 크거나 같고 나머지 절반은 작거나 같다.)
- 제 3사분위 수 (Q3) : 중앙값 기준으로 상위 50% 중의 중앙값, 전체 데이터 중 상위 25%에 해당하는 값
- 제 1사분위 수 (Q1) : 중앙값 기준으로 하위 50% 중의 중앙값, 전체 데이터 중 하위 25%에 해당하는 값
- 사분위 범위 수(IQR) : 데이터의 중간 50% (Q3 - Q1)
입니다.
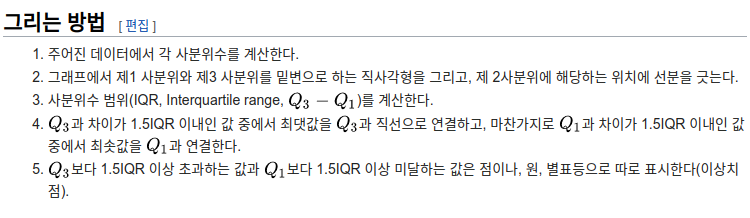
먼저, 직사각형의 윗 선분과 아랫선분의 Q3와 Q1 이라는 점, 직사각형의 중간에 그어진 검은 선이 제2사분위수(=중위수)입니다.
직사각형과 점선으로 이어진 윗 직선과 아랫직선은 최댓값과 최댓값입니다. 이 때의 최댓값은 3사분위수와 1.5QR이내 값 중 최댓값입니다. 최솟값도 동일하게 적용됩니다. 헌데 그러면 이상치 값은 최댓값과 최솟값과 밖에 있는 겁니다.
일정 범위를 벗어난 규격 외의 값은 이상치로 두고 어느 정도의 생태계 선에서만 최댓값과 최솟값을 선정하는 것으로 보입니다. 비유를 하자면, 축구를 예로 들면 현재 세계 최고의 축구 선수 할때 여러 선수를 비유하실텐데 메시와 호날두는 '신계'라고 해서 규격외 로 둡니다. 그 밑에 선수들만 비교하면서 '인간계' 최강이다 뭐 이런식으로 재밌는 비교를 하는데요. 위 박스플롯도 이와 비슷하다고 생각합니다. 너무 난놈이나 못난놈은 규격 외로 두는 것이죠. (적절한 비유인지는 모르겠지만 저는 그런식으로 생각했습니다 ㅎㅎ)
이상치값들은 그래프의 분포를 변하게 해서 우리가 데이터에 대한 오해를 하게끔 합니다. 생태계를 파괴하는 주범이랄까요? 그렇기에 박스플롯에서는 일정 범위 밖을 벗어나는 값들을 이상치로 두는 것 같습니다. 그 범위 안에서의 분포도만 데이터의 특성이 파악이 된다고 생각하는 것 같습니다 [ 아니라면 댓글로 정정해주시면 감사하겠습니다 :) ]

pandas 에 boxplot 이 있습니다. 판다스로 그래프 그릴때는 집계 함수를 먼저 적용하고 나서 그래프를 그린다고 했습니다. (물론 항상 그런건 아닙니다. 데이터프레임 상태에서 scatter plot을 그리거나 할때 굳이 집계를 할 필요는 없겠죠?)
위 집계에서는 연도별 값이 하나이기에 우리가 생각하는 박스 플롯이 나오지 않았습니다.
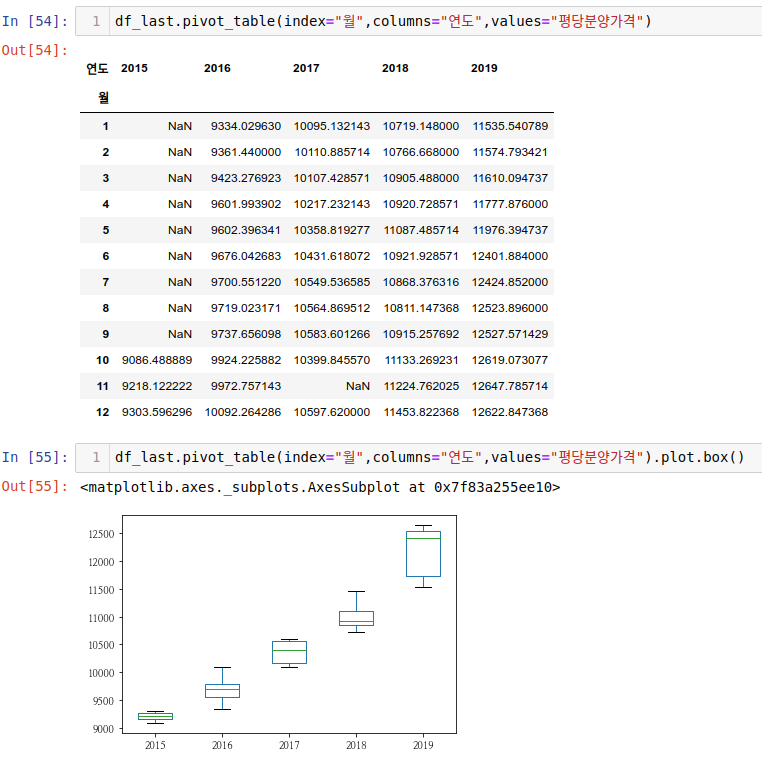
이번에는 값들이 꽤 들어있어서 우리가 흔히 보는 박스 플롯이 나왔습니다. 2015년의 경우, nan값이 많으므로 2015년은 없이 나머지 연도를 보는게 좋을 것 같습니다. 직사각형의 크기가 긴 게 있고 짧은 게 있습니다. 2019년의 경우 직사각형과 그 위의 최댓값 사이의 간격이 짧습니다. 2018년의 경우 간격이 좀 있습니다. 이는 3사분위 수와 최댓값 사이의 값이 차이가 크게 안나는 경우와 차이가 좀 나는구나 (상대적으로 볼때) 그렇게 볼 수 있습니다. 어떤 정책이나 시장의 분위기때문에 (2018년의 경우) 특정 달에는 분양가가 올랐고 (2019년의 경우) 무난하게 분양가가 증가했다라는 걸 생각해 볼 수 있습니다.
위에서는 없지만 이상치가 있다면 항상 이에 대해 원인이나 이런 걸 파악해볼 필요가 있습니다.
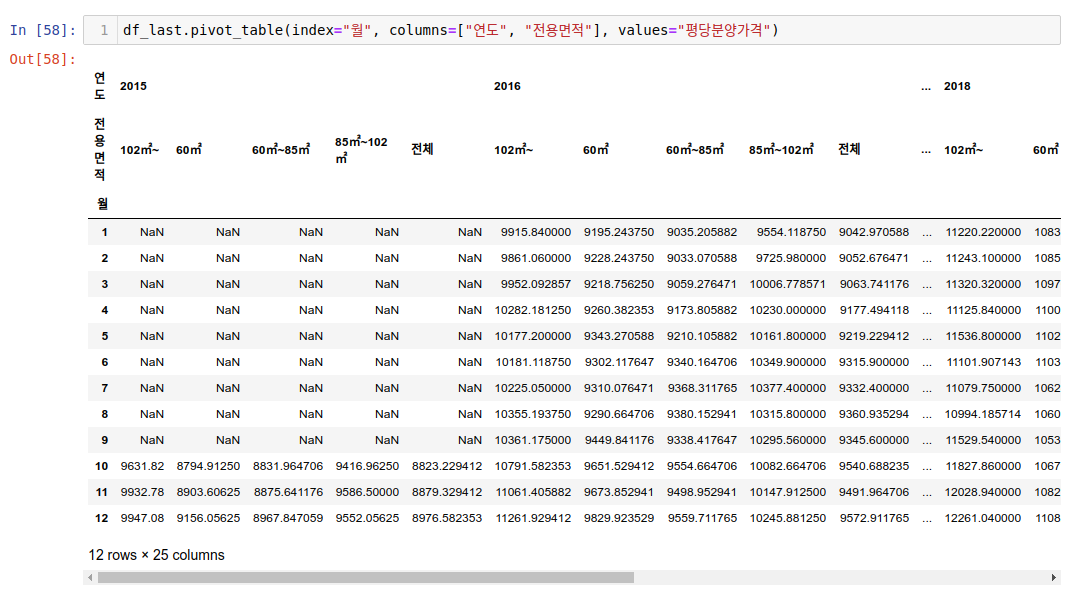
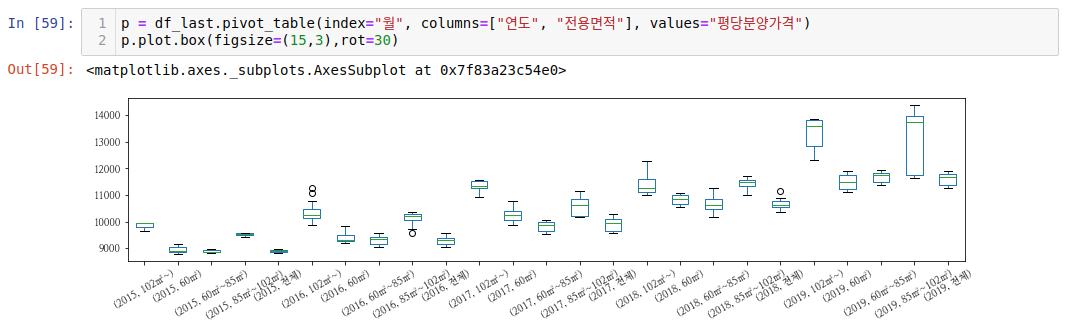
위처럼 연도별로 전용면적별 박스플롯을 그려볼 수 있습니다. 하지만 그래프의 사이즈를 크게해도 너무 촘촘해서 보기가 쉽지않은데요. 그럴 경우, 불리언추출로 보고싶은 연도의 데이터만 따로 빼서 이 데이터만을 박스플롯 그려줘도 괜찮을 것 같습니다. 몰론, 전체적으로 볼때는 위와같이 보면서 추이를 비교해볼 수 있습니다.
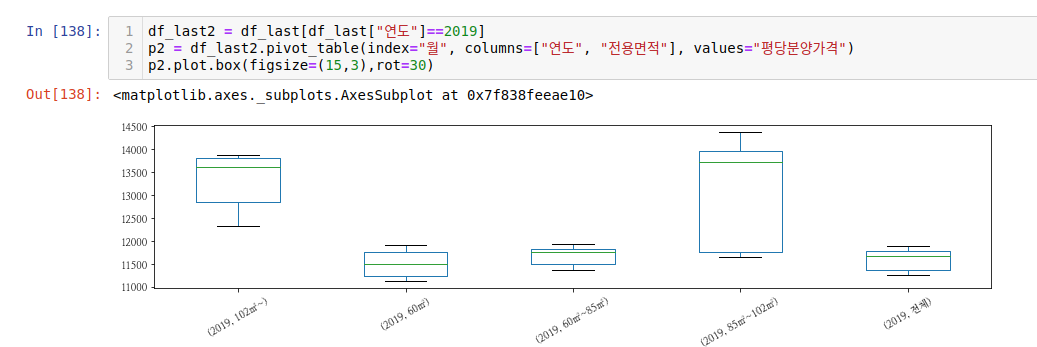
pandas 박스플롯은 이정도로 하고, 잠시 라인 플롯을 그려보겠습니다.
pandas로 라인플롯을 그려보면 2015년에 소실된 값들이 있는 것을 확인할 수 있습니다.
현재까지 pandas로 이용해서 막대그래프, 박스플롯, 라인플롯 이렇게 그려봤습니다.
Seaborn 을 그래프 그리기
이번에는 seaborn 으로 위에서 한 작업들을 해보겠습니다.
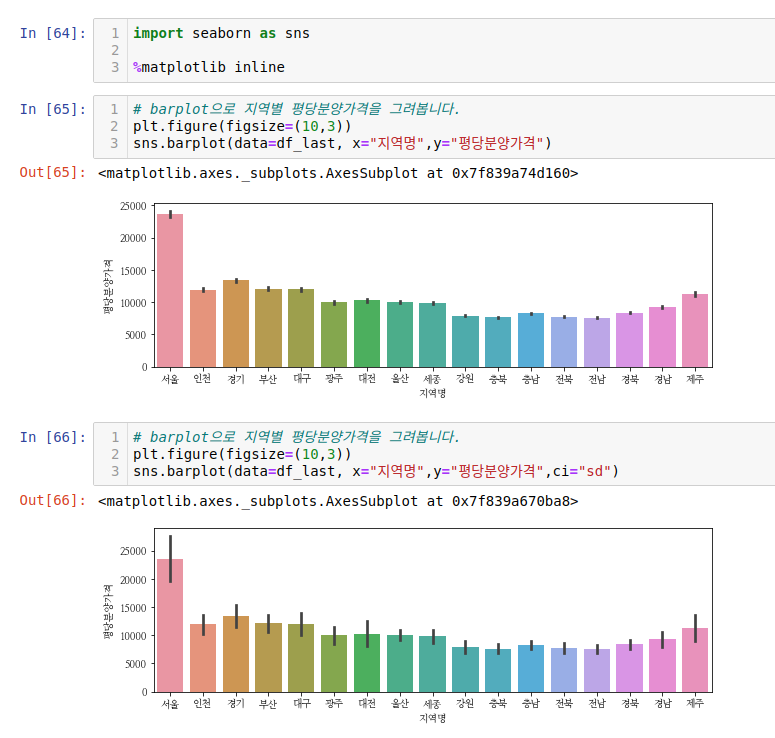
seaborn 으로 그리는 것은 좀 더 편리합니다. 집계를 해주지 않아도 알아서 해줍니다. 도움말을 보면 barplot의 경우 평균값을 기본으로 estimator로 본다고 나와있습니다. 위에서 눈여겨볼 것은
ci="sd"는 관측값의 표준편차를 그려줌. 편차 큰 곳이 막대가 큰 것을 확인가능
confidence intervals - 막대 위 검은색 막대
기본 디폴트는 95이며 이는 신뢰구간 95퍼를 의미합니다. 이상치 값을 제거한 95퍼센트 값을 샘플링했을때의 평균으로 보면 됩니다. sd는 표준편차로 ci를 설정한다는 것입니다.
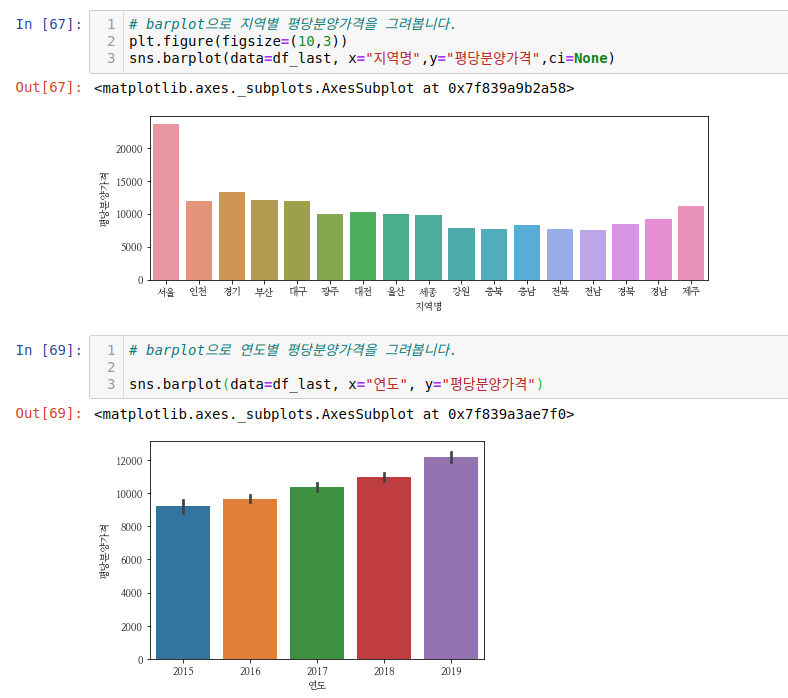
ci를 none으로 해서 그려보면 검은색 막대가 사라진 것을 볼 수 있습니다.

pandas로 라인플롯 그릴때 레전드가 그래프 내부에 있어서 보기가 안 좋았는데 이에 대한 설정은 위 코드를 참고하시면 됩니다.
다음으로 relplot 과 catplot을 보겠습니다.relplot 은 범주형 데이터들을 세부적으로 subplot으로 다양하게 그려주는 그래프입니다. 각각의 지역별로 평균값을 구해서 그래프를 그려줍니다. 여기선 col 옵션과 col_wrap 옵션이 장점입니다. 이 옵션들을 이용해서 그리지 않으면 기존에 bar, line 그래프 그리는 것과 유사하게 나옵니다.
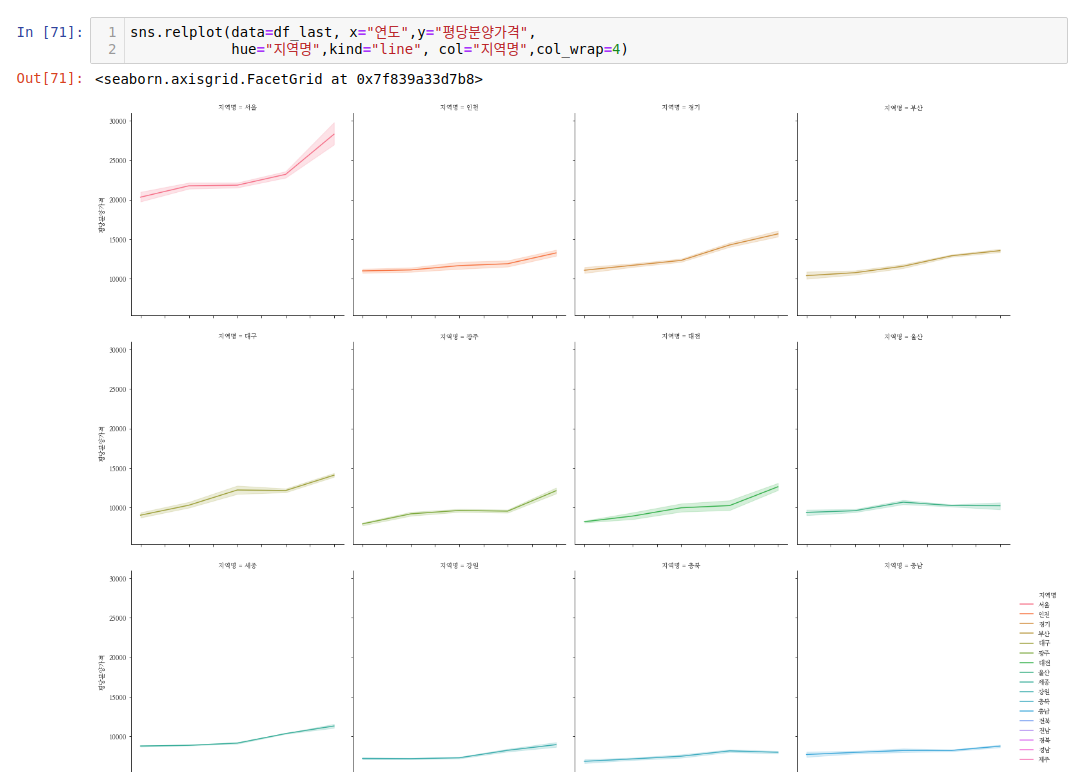
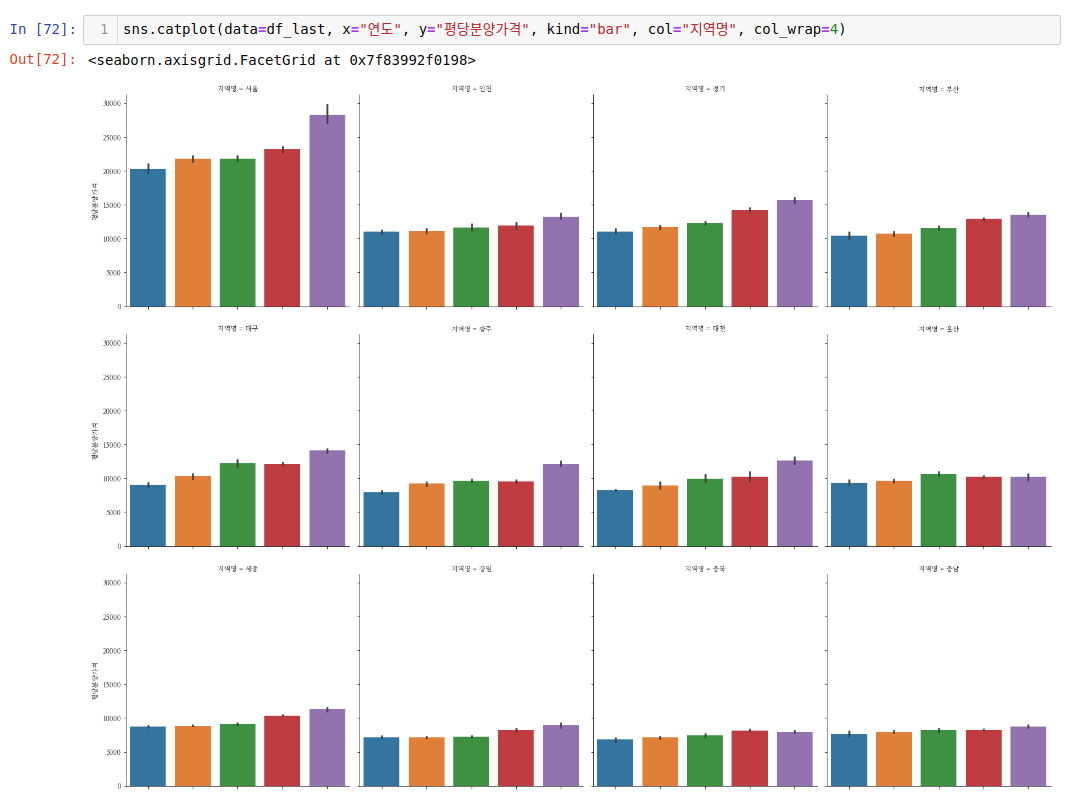
subplot으로 그릴 때는 위 2가지 메서드를 사용해서 그려주면 됩니다.
seaborn - boxplot과 violinplot
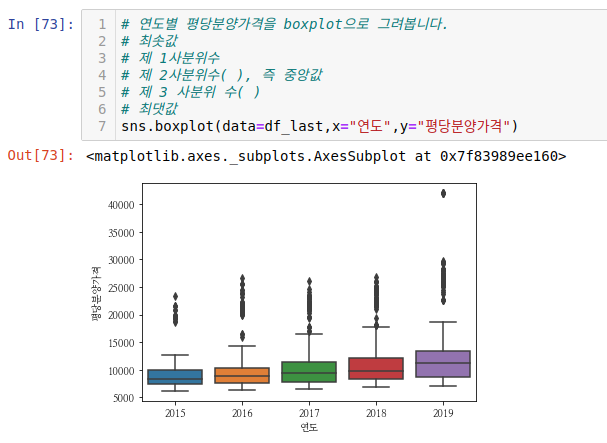

전용면적별로 연도별로 분양가격을 보니 이상치 값들이 꽤 보이고 편차들도 확인할 수 있습니다.
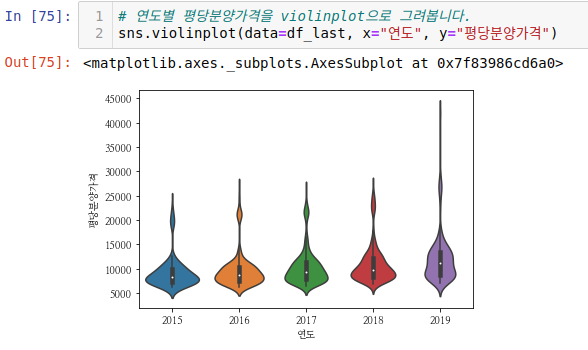
violinplot 입니다. 다양한 형태의 그래프를 보면서 왜 쓰는지를 잠시 정리해보겠습니다. 위에서 bar 그래프를 그릴 때는 평균값에 대한 것을 막대그래프로 먼저 보았습니다. 이는 데이터의 분포를 알기 어렵다는 단점이 있어서 boxplot으로 이를 좀 더 자세히 알 수 있었습니다. 하지만 박스플롯도 위로 올라가서 다시 보면 직사각형 안의 데이터 분포도(1사분위수-3사분위수 사이)를 알기가 어렵습니다. 이에 대한 보완을 하기 위해 violinplot 을 사용합니다. 값의 분포를 좀 더 자세히 확인할 수 있습니다.
밀도추정그래프를 세로로 그린 모양이 violineplot 입니다.
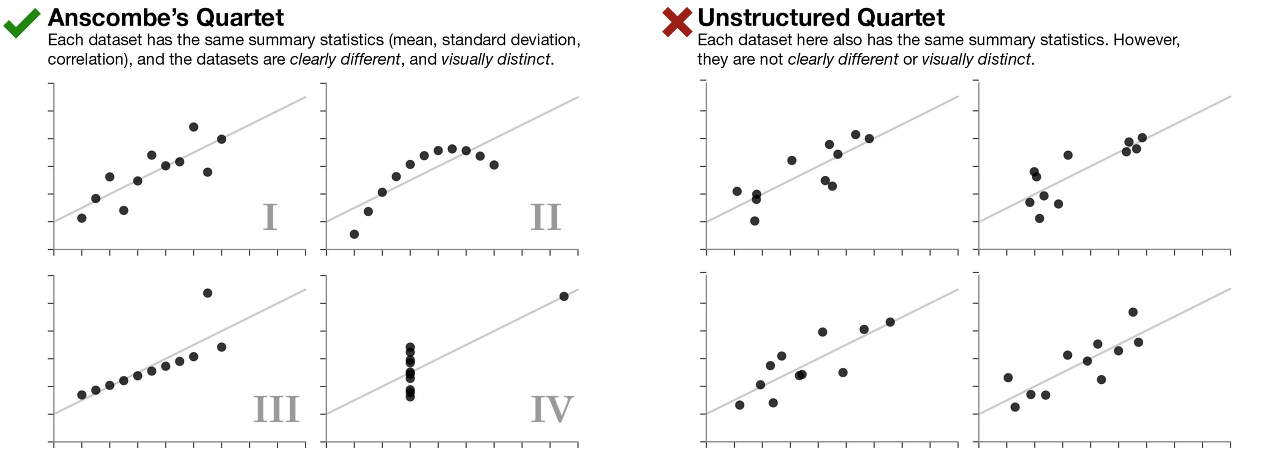
Anscombe's Quartet 은 요약된 데이터 수치(평균,표준편차 등등)만으로는 데이터의 분포를 파악할 수 없다는 것을 보여줍니다.
아래는 데이터사우르스 라고 해서 다 아래와 같은 통계 수치를 가지고 있는 데이터의 분포도들 입니다.
이 블로그의 출처는 맨 아래 첨부해놓을테니 한 번 읽어보시면 좋습니다.

자, 이제 아래 그림들이 중요합니다.
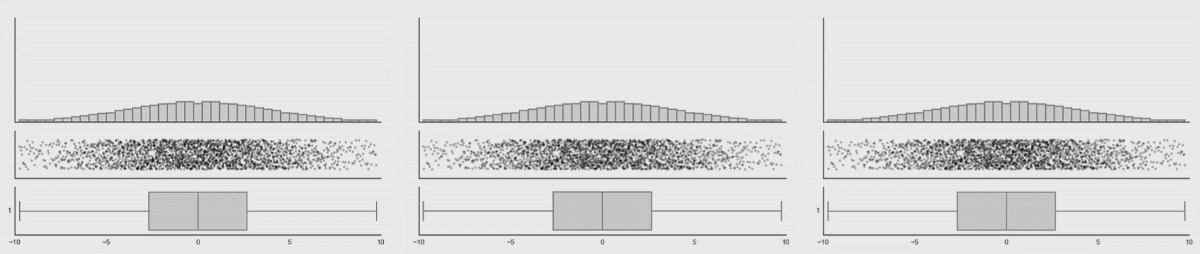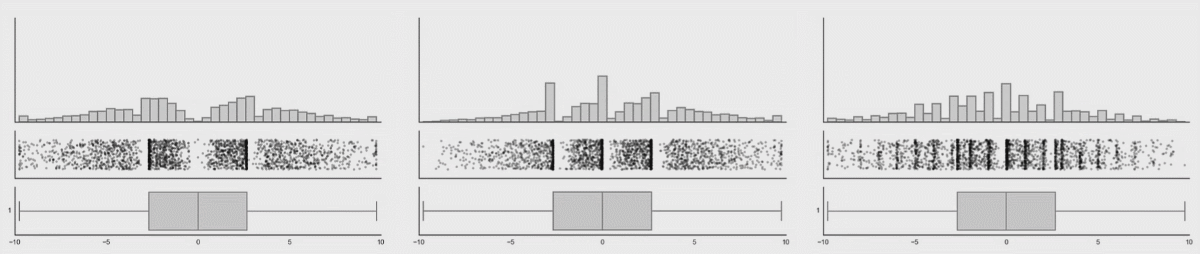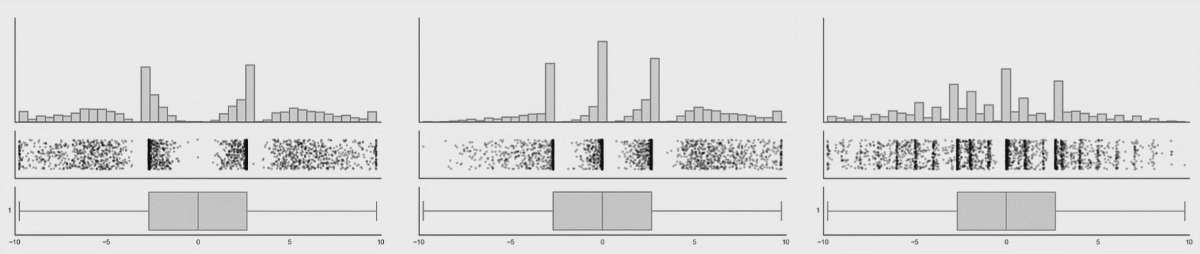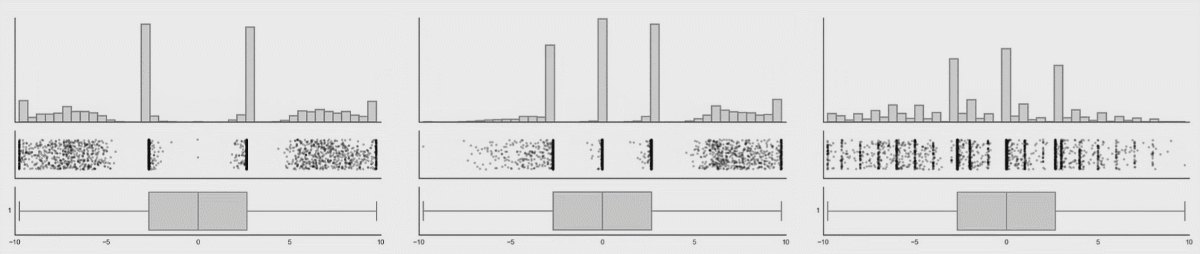
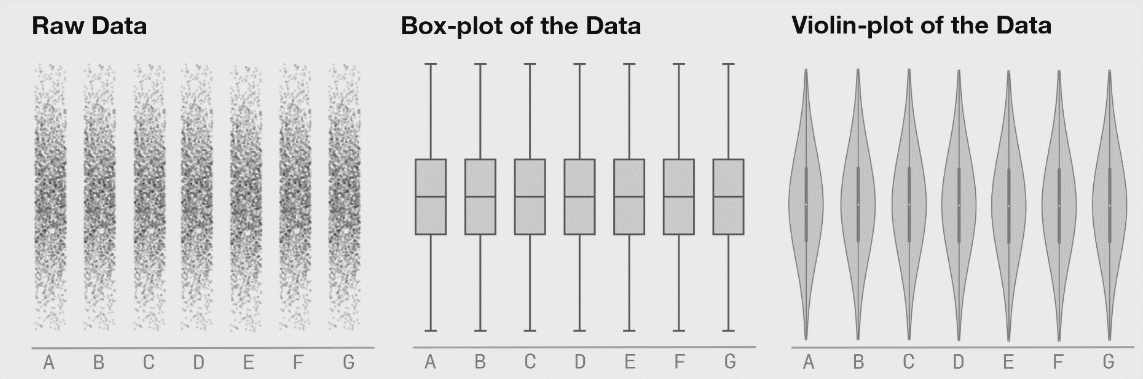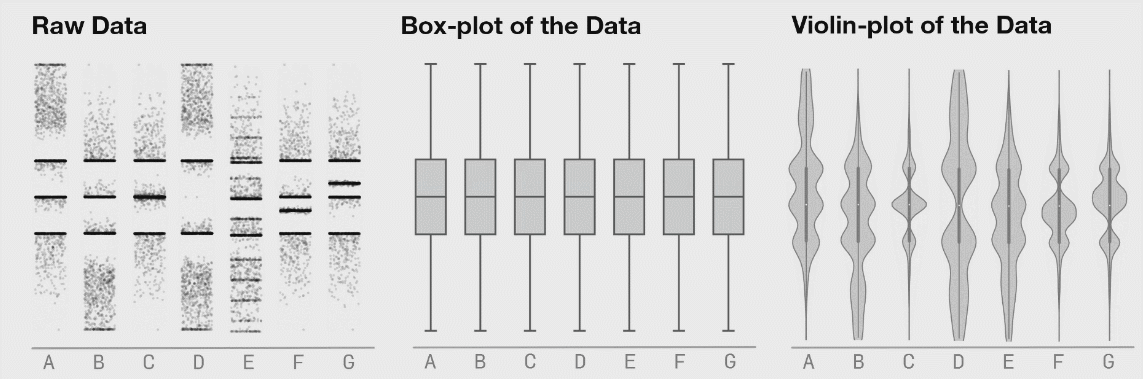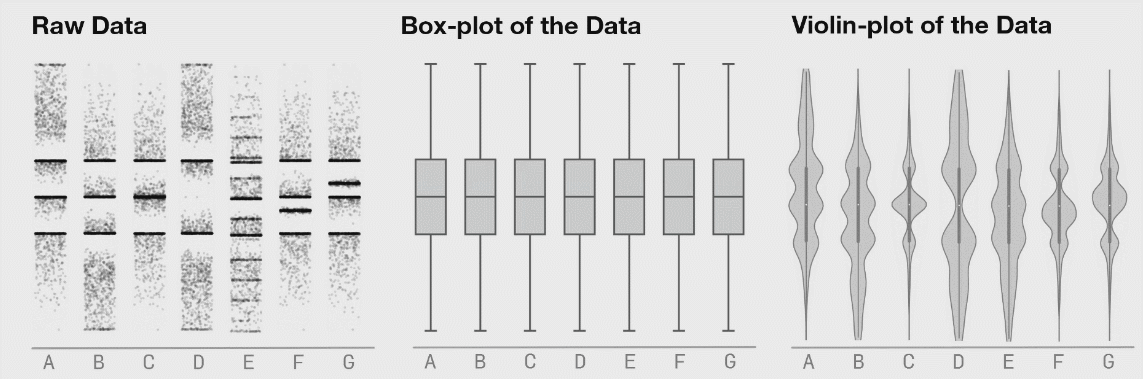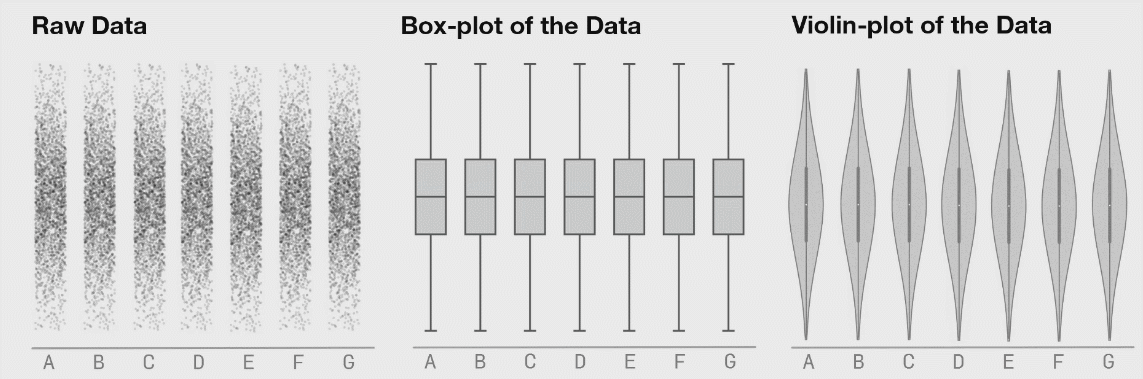
데이터의 분포가 바뀌어도 박스플롯은 변하지 않음을 위에서 확인할 수 있습니다. 이러한 것을 보완해주는 것이 Violine plot 입니다. 바이올린 플롯은 로우 데이터의 변화를 표시해주고 있음을 확인할 수 있습니다.
여기서 결론!
boxplot 은 데이터의 분포를 보여주지 못하기에 이에 대한 보완책으로 violine-plot이 나왔다! 입니다.
seaborn - lmplot , swarmplot

regplot은 scatterplot에 회귀선을 그어주는 그래프입니다.
scatter plot 은 x축과 y축에 넣은 데이터가 모두 수치형 데이터일 때 사용합니다. 데이터의 분포를 보기 위해서 그려보는 것입니다. 대각선이 그려진다는 것은 양의 상관관계가 있는 것으로 볼 수 있습니다. 하지만 위에서는 약한 상관관계 정도로 볼 수 있습니다.
회귀선도 어떤 데이터냐에 따라 시기별로도 상관관계가 달라질 수 있습니다.
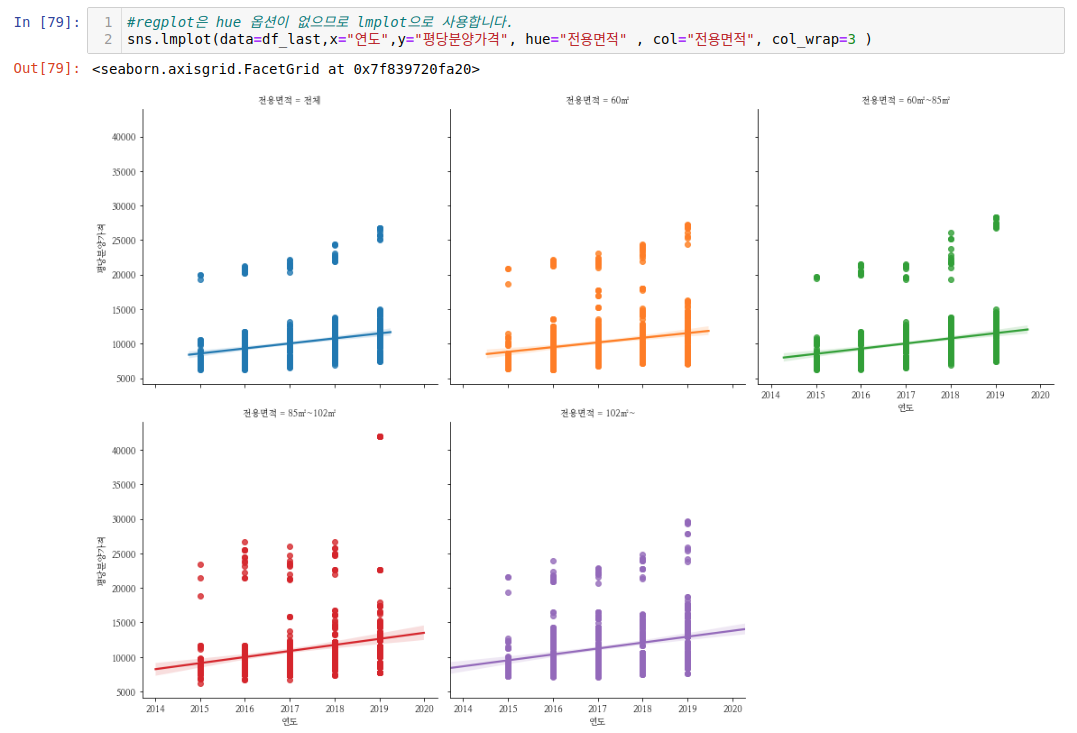
regplot 은 hue 옵션이 없습니다. 그래서 lmplot 을 씁니다. subplot 옵션들을(=col, col_wrap)을 이용해서 나눠서 그려보는 것이 보기가 좋습니다. lmplot 은 둘 다 수치데이터일 떄 그리는 것이 적당합니다. lmplot은 x축, y축 둘 다 수치데이터일때 그리는 것이 좋습니다. 데이터의 분포도르 알기 어렵다는 단점이 있습니다. 위에서 '연도'데이터는 수치형이라기 보다는 카테고리형 데이터에 가깝습니다. 이럴떄는 swarmplot이 적당합니다.

데이터의 분포도를 좀 더 자세히 알 수 있어서 swarmplot이 좋긴 합니다. 하지만 swramplot의 단점은 점을 일일히 찍기때문에 시간이 오래 걸립니다. 따라서, 너무 많은 데이터의 경우 swarmplot으로 그리는 것이 적당하지 않을 수 잇습니다. 시간이 오래 걸리기 때문이죠.
이상치 보기
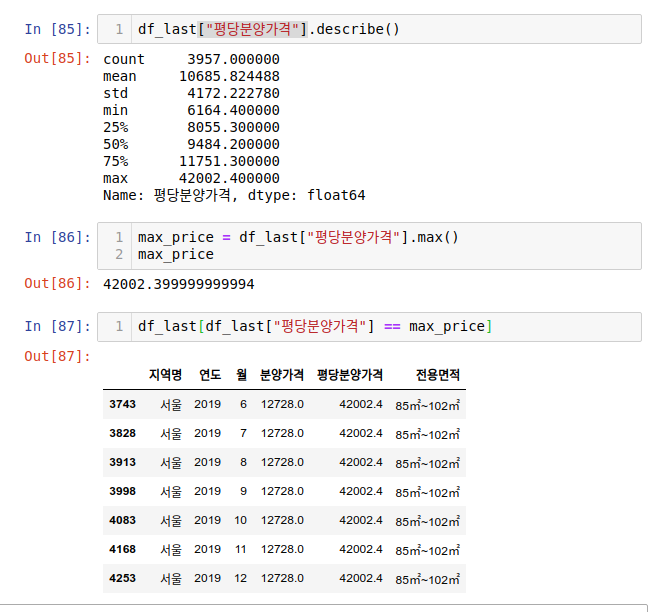
평균가격과 최대가격이 차이가 상당하고 3사분위값과도 맥스값이 차이가 상당합니다. 중앙값에 비해서 평균값이 높은 것을 확인할 수 있습니다.
수치 데이터 히스토그램
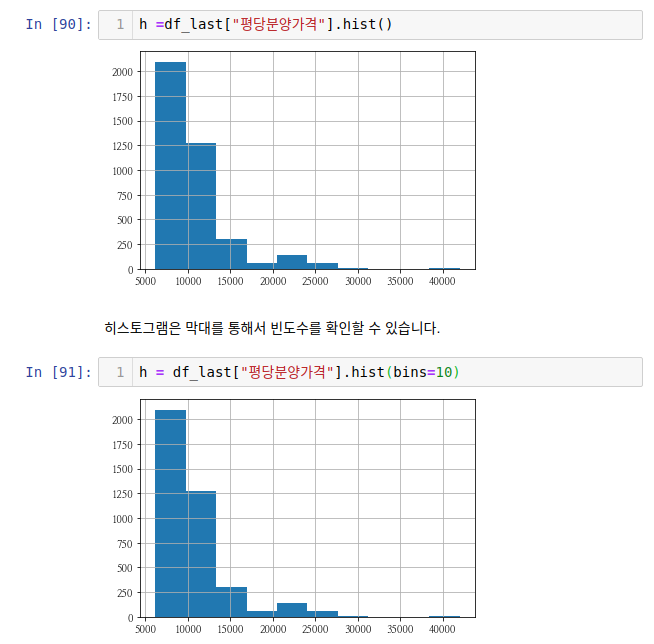
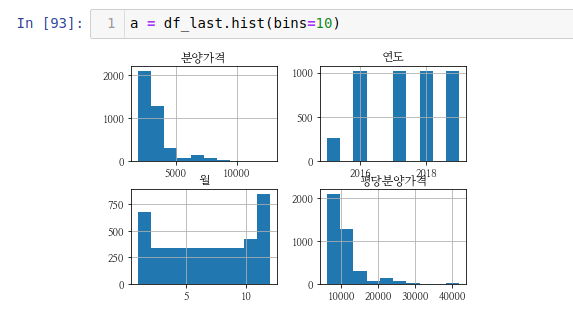
bins=10을 주면 막대를 10개의 구간에 나눠서 담는다는 뜻입니다. 그리고 그 구간에 등장하는 빈도수를 셉니다. 위 히스토그램에서는 2015년도의 데이터가 많이 없음을 확인할 수 있고 평당분양가격도 대부분 10000과 15000 사이에 많음을 확인할 수 있습니다.
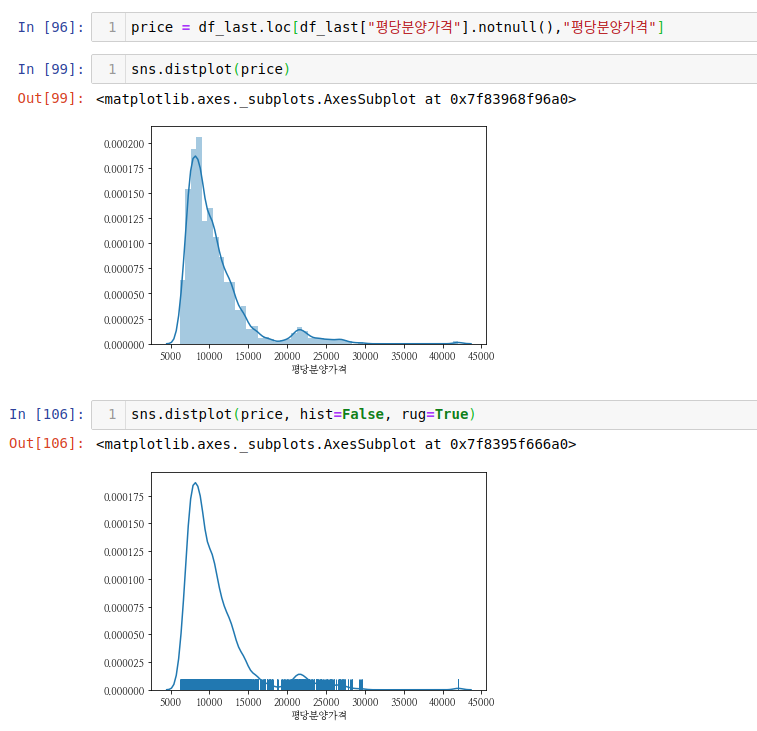
distplot의 경우 매개변수에 x,y 라는 옵션이 없습니다. 그 대신, 시리즈 데이터를 넣어줘야합니다. 이 때, 결측치가 있으면 value error가 발생하므로 이를 전처리 해줄 필요가 있습니다.
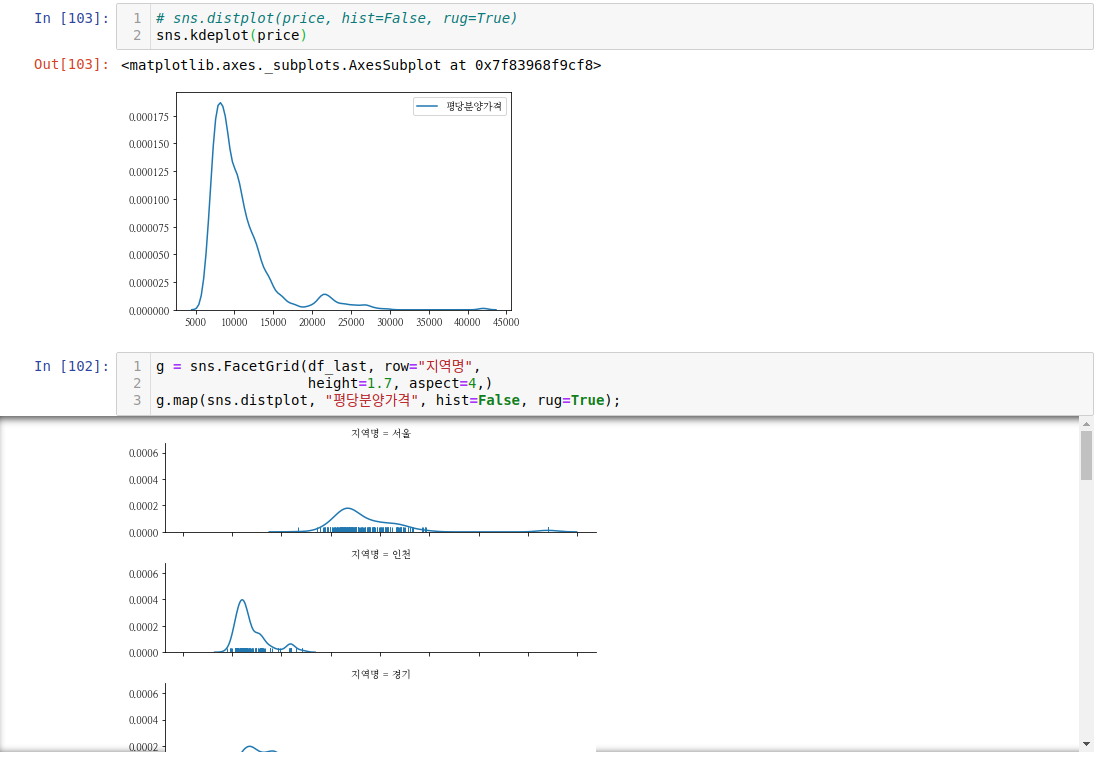
kdeplot 으로도 비슷하게 그래프를 그릴 수 있습니다. kdeplot에서는 hist,rug 옵션이 없습니다.
이런 식으로 분양 가격의 분포를 볼 수 있습니다. 지방은 좌측에 많은 분포가 있고, 서울은 가운데 분포가 많이 되어있습니다. 이상치 때문인 것으로 보입니다.
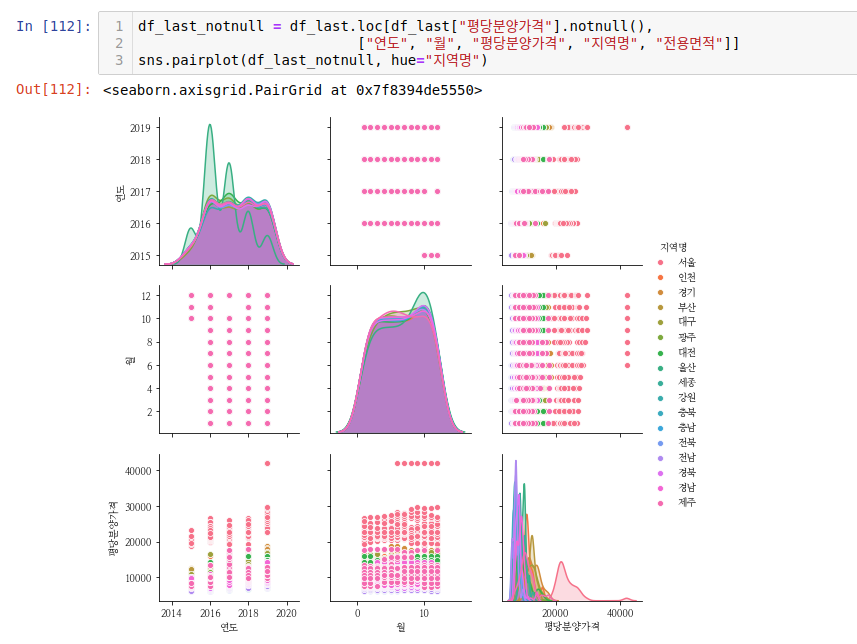
위 그래프에서는 빈도수를 표현하는데, 특정 월이랑 연도 지역이 많아 보입니다. 이런 식으로 시각화를 통해 데이터의 분포를 확인할 수 있었습니다.
이상 공공데이터 아파트 분양 분석 2단계를 마치겠습니다 :)
실습 파일
https://github.com/JangDaehyuk/basic_data_analysis_tip
위 깃허브에서 '~리뉴얼 part2'를 다운받아서 해보시면 됩니다:)
-참고 출처-
https://autodeskresearch.com/publications/samestats
The Datasaurus Dozen - Same Stats, Different Graphs | Autodesk Research
autodeskresearch.com
https://ko.wikipedia.org/wiki/%EC%83%81%EC%9E%90_%EC%88%98%EC%97%BC_%EA%B7%B8%EB%A6%BC
상자 수염 그림 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 기술 통계학에서 '상자 수염 그림'(box-and-whisker plot, box-and-whisker diagram) 또는 '상자 그림'(box plot, boxplot)은 수치적 자료를 표현하는 그래프이다. 이 그래프는 가공하지 않은 자료 그대로를 이용하여 그린 것이 아니라, 자료로부터 얻어낸 통계량인 5가지 요약 수치(다섯 숫자 요약, five-number summary)를 가지고 그린다. 이 때 5가지 요약 수치란
ko.wikipedia.org
https://github.com/corazzon/open-data-analysis-basic
'데이터분석 > 데이터시각화' 카테고리의 다른 글
| matplotlib 한글폰트 설정하기 (0) | 2020.02.28 |
|---|---|
| python 데이터 시각화 Matplotlib 기본1 라벨,범례,틱,스타일,타이틀 (0) | 2020.01.01 |

