크롤링을 다시 공부해보고 싶어서 스터디한 내용을 정리해보도록 하겠습니다.
2020년 4월 19일 실습한 내용입니다.
1) selenium , chromedriver 설치
크롤링에 맞게 세팅을 하겠습니다.
우선 저의 경우는 python3.6 의 가상환경을 활성화한뒤 selenium 을 설치하겠습니다.
# 패키지 설치하기
$ conda install selenium
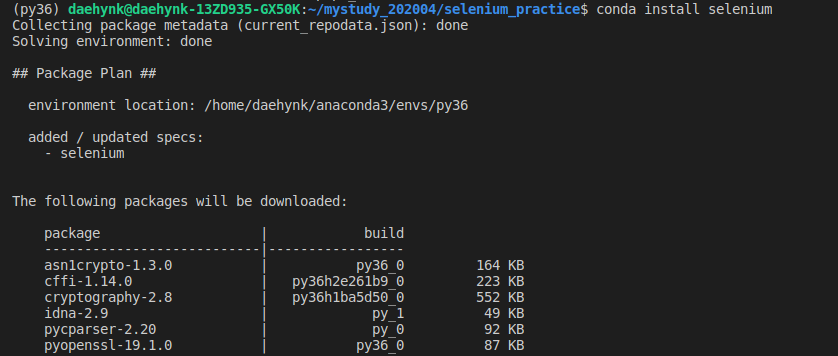
# 패키지 설치 확인
$ conda list

이제 크롬 드라이버를 다운 받습니다.
크롬 버전을 확인하겠습니다.
크롬을 열고 우측 상단의 세로로 점이 3개 찍혀있는 아이콘을 누르고 help 누르고 about chrome 누르면 바로 나옵니다 :)
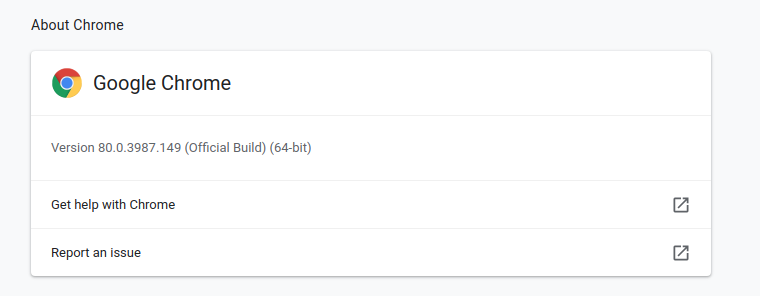
저의 경우는 위와 같습니다.
chrome driver 를 구글에 검색하셔서 본인 컴퓨터 버전에 맞는 드라이버를 다운받아주세요.
저는 리눅스에서 실습하므로 리눅스용으로 다운받았습니다.
vscode 에디터에서 작업을 하겠습니다.
작업을 진행할 디렉토리를 하나 열어주시구요.
거기에 다운받은 크롬드라이버를 압축해제해서 넣어주세요.
2) selenium 으로 url 열고 검색어 입력 후 엔터까지 누르기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# chrome 으로 드라이버 열기
driver = webdriver.Chrome('./chromedriver')
url = 'https://google.com'
driver.get(url)
우선 크롤링에서는 태그 찾는 게 중요하며 익숙해져야 합니다.
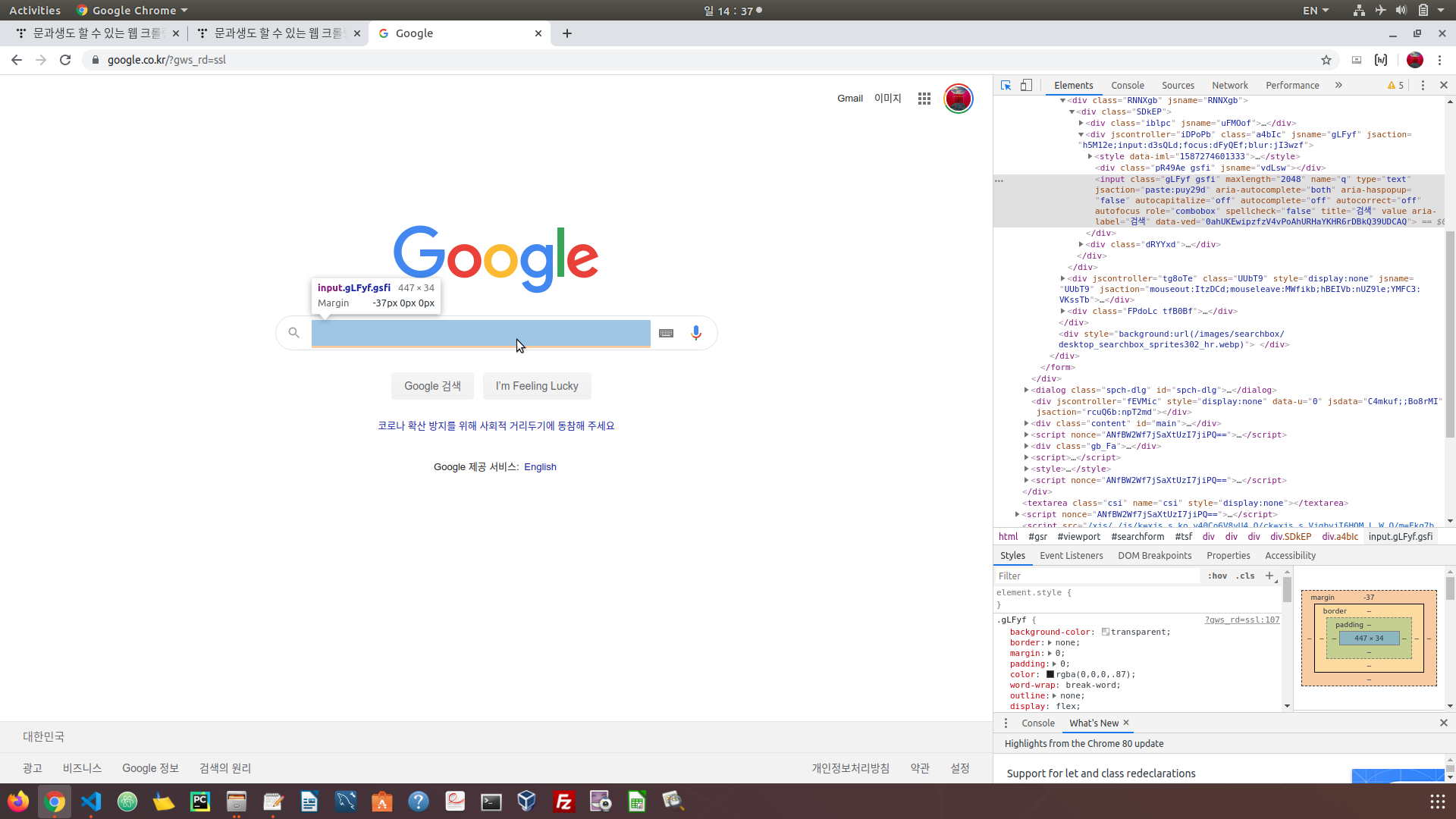
F12 를 누르면 검색 모드가 됩니다. 검색 모드에서 상단바에서 제일 좌측에 화살표 아이콘이 보입니다. 이를 누른 뒤에
검색 칸에 마우스를 옮기면 해당 부분의 태그가 보입니다. 이렇게 태그를 통해서 자동화를 시작합니다.
아래의 코드는 구글 검색에서 '파이썬'을 입력 후 엔터를 누르고 나오는 창을 기준으로
LC20lb 라는 태그를 가진 모든 css를 선택하고 그곳에서 1번째 인덱스(인덱스는 0부터 시작하는거 알죠? ㅎㅎ)
에 위치한 값을 클릭하라 라는 의미입니다.
# 클래스니깐 공백대신 . 점으로 연결해줍니다.
driver.find_element_by_css_selector('.gLFyf.gsfi').send_keys('파이썬')
# 키보드에 있는 Enter를 누름
driver.find_element_by_css_selector('.gLFyf.gsfi').send_keys(Keys.ENTER)
# 찾은 부분을 click
# driver.find_element_by_css_selector('.LC20lb.DKV0Md').click()
# 태그가 동일한 게 여러 개 있을 경우(elements로 하고)
# 리스트의 인덱스라고 보고 0번째부터 시작해서 원하는 n번째의 수를 지정 해주면 됨
driver.find_elements_by_css_selector('.LC20lb')[1].click()
별도의 driver.close() 명령을 넣어주지 않으면 팝업된 selenium 창은 수동으로 종료해주셔야 합니다.
3) selenium,beautifulsoup 을 통한 검색어 입력 후 , 링크, 경로 읽어오기.
아래 코드를 실행해보겠습니다.
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
baseUrl = 'https://www.google.com/search?q='
plusUrl = input('무엇을 검색할까요? : ')
# 한글을 변환해주는 인터넷 양식에 맞게 quote_plus
url = baseUrl + quote_plus(plusUrl)
# print(url)
driver = webdriver.Chrome('./chromedriver')
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html)
r = soup.select('.r')
#print(type(r)) # <class 'bs4.element.ResultSet>
for i in r:
print(i.select_one('.LC20lb.DKV0Md').text)
#print(i.select_one('.ellip').text)
print(i.select_one('.iUh30.bc.tjvcx').text) # 링크가 아닌 사이트 들어가서의 경로
#print(i.select_one('.iUh30.bc').text)
print(i.a.attrs['href']) #
print()
driver.close()
beautifulsoup 를 설치해야 한다면 맨 처음에 한 명령어 또는 pip install 로 설치하시면 됩니다.
quote_plus 메서드는
urllib.parse.quote_plus(string, safe='', encoding=None, errors=None)¶
quote()와 유사하지만, URL로 이동하기 위한 쿼리 문자열을 만들 때 HTML 폼값을 인용하는 데 필요한 대로 스페이스를 더하기 부호로 치환하기도 합니다. safe에 포함되지 않으면 원래 문자열의 더하기 부호가 이스케이프 됩니다. 또한 safe의 기본값은 '/'가 아닙니다.
예: quote_plus('/El Niño/')는 '%2FEl+Ni%C3%B1o%2F'를 산출합니다.
라고 파이썬 3.8.2 공식문서에 나오는데요.
한글로 검색하고 링크를 보시면 이상한 문자로 길게 써져있는 걸 볼 수 있습니다. 한글 자체를 웹 상에서는 해석이 안되니깐 그렇게 변환되는건데요. 위 코드에서 quote_plus 가 그렇게 변환해주는 겁니다.
태그를 살펴보겠습니다.
링크는 r 클래스에 a href 부분에 들어 있고, 제목은 h3 class 부분에 있습니다.
아래처럼 내가 원하는 텍스트 부분의 태그를 계속 확인하시면 됩니다.
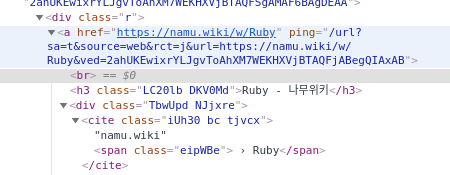
3) 에서 실습한 코드에서 검색어를 묻는 부분에서 다른 검색어를 입력하면 아마 작동을 안할겁니다.
그 이유는 위에서 잡은 태그들은 구글에서 '파이썬'이라고 검색했을 때 나오는 결과창을 기준으로 하기 때문입니다.
다른 검색어를 입력하면 다른 태그들로 변할 것이며 이는 '검사'를 통해서 확인하셔야 합니다.
크롤링은 기본 원리는 비슷하지만, 이런 식으로 태그를 일일이 맞춰서 잡아줘야됩니다. 만약 수십 페이지의 문서에서 무언가를 다운받거나 해야될때 이를 활용해서 짠다면 시간을 절약할 수 있습니다. 기본적인 틀은 똑같으니 태그만 잡아서 자동화해주면 크롤링이 됩니다.
태그 잡는건 쉽지 않지만 여러 번 하다보면 익숙해집니다.
물론 전 아직 안 익숙합니다 :)
계속 연습을 해야겠죠.
이번 실습은 유튜브 사이트를 보고 실습을 진행했습니다.
자세한 설명을 원한다면 아래 유튜브 채널에서 직접 강의 영상을 보시는 걸 추천드립니다 :)
--참고--
https://www.youtube.com/watch?v=hKApZHK_fOQ&t=3s
'Python_programming > 크롤링' 카테고리의 다른 글
| 크롤링 입문(2) selenium - 시간창 대기 ,팝업창 닫기 (2) | 2020.04.19 |
|---|
