https://www.kaggle.com/c/word2vec-nlp-tutorial
Bag of Words Meets Bags of Popcorn
Use Google's Word2Vec for movie reviews
www.kaggle.com
자연어처리 입문으로 할 때 많이 쓰는 튜토리얼인 Bag of Words Meets Bags of Popcorn 을 다뤄보겠습니다.

위의 링크를 눌러서 'Data'를 누르시면 sources 를 받을 수 있습니다. (로그인이 되어있어야 다운이 될거에요~)
그리고 지금부터 하는 이 튜토리얼 코드는 순수하게 제가 하는 것이 아닌
인프런의 '[NLP] IMDB 영화리뷰 튜토리얼' 강의를 듣고 따라하면서 제가 복습 및 정리하는 내용입니다 :)
1. 데이터 불러서 살펴보기

우선 데이터를 부릅니다. 3가지의 칼럼이 눈에 보입니다. id는 말그대로 유저 아이디이구요. 저기서 sentiment는 긍부정을 나타냅니다. 1 은 긍정을 의미하며 0 은 부정을 의미합니다.
quoting = 3 은 쌍따옴표를 무시한다고 되어 있습니다. 무시한다는 건 그대로 가져온다는 것으로 보입니다.

quoting 을 빼고 read_csv 를 하니 ""(쌍따옴표)가 생략되었습니다.

원본 데이터를 그냥 열면 위처럼 쌍따옴표를 확인할 수 있습니다.
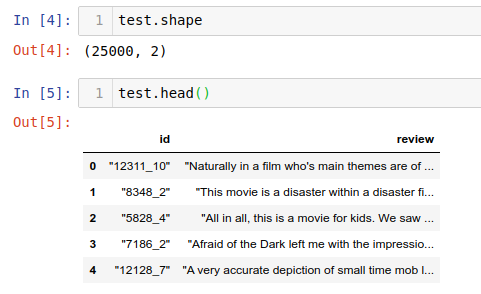
test data를 보면 sentiment 칼럼이 보이지 않습니다. 이것은 train에서 모델링을 하여 학습을 한 뒤 정답을 메기기 위해 그렇습니다.

null 값도 안 보이고 train 셋의 정답의 비율도 5:5로 정말 예제로써 완벽한 데이터 셋임을 확인할 수 있습니다 :)
그리고 head, tail, info, describe ,shape 은 데이터를 살펴보는 기본 5총사입니다. 항상 (pandas로) 데이터를 부른 뒤에는,
이 5총사를 써서 데이터를 살펴봐야 합니다! (기본 중의 기본임을 다시 한 번 상기시키기 위해...)
describe의 경우 숫자 데이터 타입만 보게끔 되어있지만,

저렇게 옵션을 걸어주면 문자 타입의 칼럼도 describe 해줍니다.
2. 데이터 정제하기

리뷰를 보면 태그가 섞여 있음을 확인할 수 있습니다.

beautifulsoup을 불러서 태그를 제거해 보겠습니다. 뒤에 인자인 "html5lib" 를 html구문을 분석해주는 api인데요.
("lxml", "lxml-xml", "html.parser", or "html5lib") 정도가 있습니다. 파이썬 크롤링을 공부할 때 제일 초반에 배우는 내용입니다 :)
어쨌든 구문분석을 한 뒤에 .get_text() 메소드를 이용하면 한글만 쏙 가져옵니다.
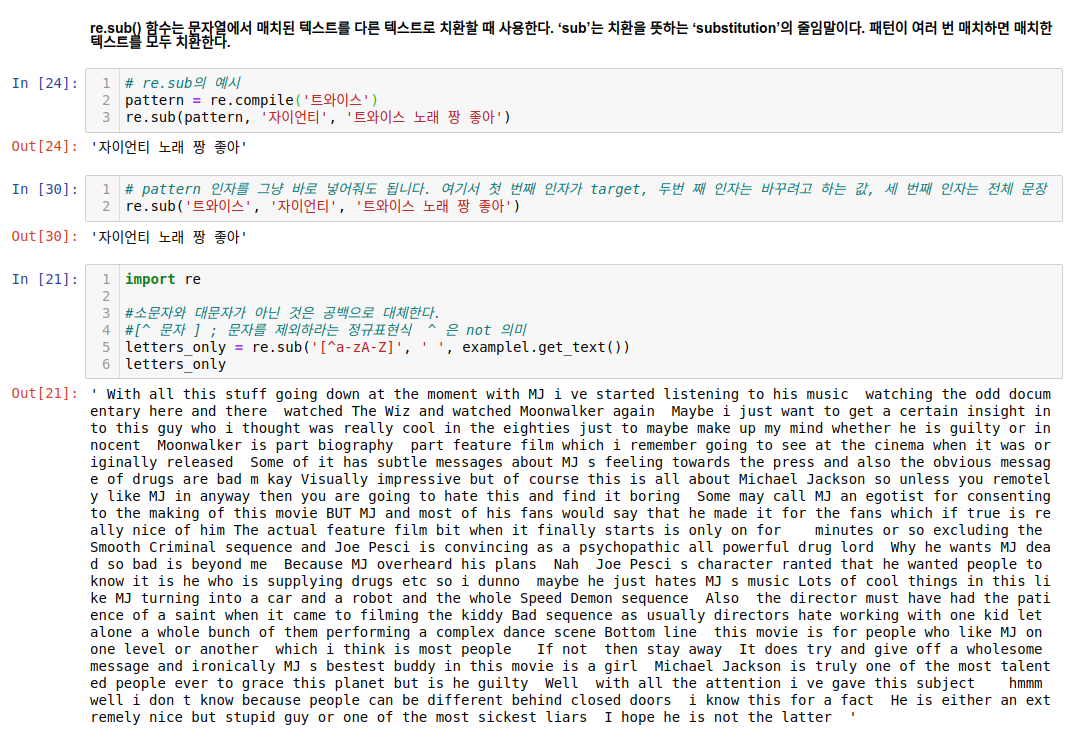
다음은 정규표현식 라이브러리를 이용하여 re 를 이용해서 특수문자를 제외합니다.
re.sub을 사용하는 예시는 구글링하면 쉽게 찾아보실 수 있습니다. 위에서선 .compile을 이용하는 방식과 바로 re.sub에 바꿀 값을 넣는 등의 2가지 활용 방법을 예시로 썼습니다.
// 참고로 위의 '트와이스'와 '자이언티'는 제가 만든 예시이니 직접해보시면 익혀보시길! :)

.lower() 을 이용해서 모두 소문자로 바꿔주고 .split()를 합니다. 하지만 with, all, this 와 같은 대명사나 전치사는 어떠한 정보를 갖고 있다고 보기 힘듭니다. 그러니 이러한 불용어(정보가치가 없는 말 - 저만의 정의입니다 ㅎ)를 날려줘야 합니다!

일반적으로 코퍼스에서 자주 나타나는 단어는 학습 모델로서 학습이나 예측 프로세스에 실제로 기여하지 않아 다른 텍스트와 구별하지 못합니다. 예를들어 조사, 접미사, i, me, my, it, this, that, is, are 등 과 같은 단어는 빈번하게 등장하지만 실제 의미를 찾는데 큰 기여를 하지 않는다. Stopwords는 "to"또는 "the"와 같은 용어를 포함하므로 사전 처리 단계에서 제거하는 것이 좋습니다. NLTK에는 153 개의 영어 불용어가 미리 정의되어 있다. 17개의 언어에 대해 정의되어 있으며 한국어는 없습니다.
영어는 친절하게도 nltk.corpus 안에 불용어가 있습니다. 한국어는 없어요... 그래서 한국어는 도메인마다 맞게 불용어 리스트를 만들어서 클래스로 만들어서 날려주는 형태로 만들어 줘야합니다. 일부 국내 대학이나 대학원에서 감성사전을 만든 논문이나 시도를 볼 수 있는데 이게 본인들이 하는 프로젝트와 성격이 맞으면 쓸 수 있지만 다르면 쓰기 힘든 걸로 알고 있습니다. 이게 참 아쉽죠...ㅠㅠ 또, 저작권도 있어서 쓰려면 해당 연구실에 문의하고 돈을 주고 써야 되는 경우도 있는거 같습니다...이래서 언어학 전공자랑 심리학 전공자가 자연어처리 프로젝트를 할 땐 필요한 거 같습니다... ㅠ_ㅠ....멀고도 험한 nlp...
2.2 데이터 정제하기 - 어간추출(스테밍)

nltk 에는 포터 스테머, 랭커스터 스테머가 있습니다. maximum을 어간추출한 결과를 보면 두 스태머가 다른 결과를 보여줌을 알 수 있습니다.

해당 튜토리얼에서는 snowballstemmer을 이용해서 어간 추출을 진행하였습니다!
자, 그러면 위에서 진행했던 데이터 정제 메서드들을 함수로 만들어 보겠습니다!
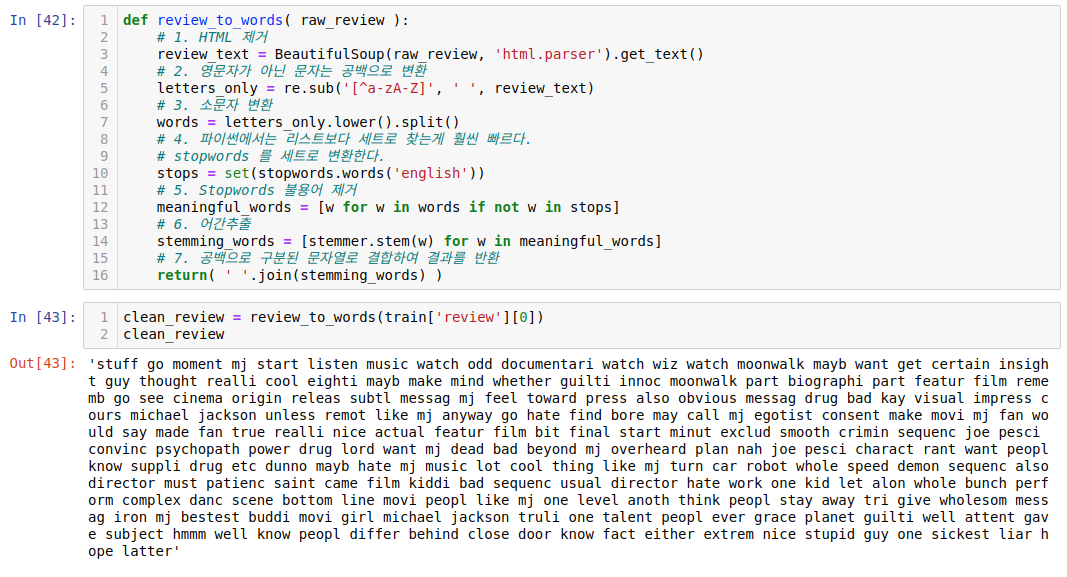
아주 깔끔하게 정제가 되는 걸 확인할 수 있습니다.

전체 리뷰가 2만5천개 였습니다. 이를 for문으로 돌려서 하니 1분 정도 소요됐네요. (제 cpu는 i5, 램은 8G입니다)
*** 여기서 잠깐! 좀 더 시간을 줄이는 방법이 없을까? ***
from multiprocessing import Pool

아주아주 유용한 꿀팁인데요. 병렬처리가 가능한 라이브러리가 있습니다. 이를 통해서 시간이 25초정도 줄었음을 볼 수 있습니다!
(자세한 건 코드를 참고 및 캡쳐에 나온 링크(아래)로 고고!)
http://www.racketracer.com/2016/07/06/pandas-in-parallel/


정제된 데이터를 시각화 해보았습니다.
(폰트 설정의 경우는 저는 우분투를 쓰고 있어서 따로 조은님의 폰트 설정 동영상을 보고 따라했습니다! 혹시, 리눅스 유저를 위해 나중에 그래프 그릴 때 폰트 설정하는 법은 따로 다루겠습니다! 아니면 초반에 소개한 조은님의 유튜브나 강의에 보면 폰트 설정 하는 법은 무료로 블로그 포스팅이나 영상으로 게재한 게 있으니 그거 보시고 따라하시면 됩니다! )
IMDB 자연어처리 입문 튜토리얼 1단계 데이터 정제를 이상으로 마칩니다!
다음 시간에는 벡터화와 모델링 하는 것을 해보겠습니다~!
'머신러닝,딥러닝 > 자연어처리(NLP)' 카테고리의 다른 글
| 사이킷런 TFIDF 와 코사인유사도 로 문서 유사도 구하기 (0) | 2020.04.21 |
|---|---|
| word2vec 이해를 위한 개념 정리 part1 (0) | 2019.12.22 |
| 캐글 자연어처리(NLP) 튜토리얼 입문 2. 머신러닝 모델링 - 백터화 (0) | 2019.12.19 |


