파이썬 문자열 표기법을 보면 형식 문자열이라고 해서 % 기호의 좌측에 값이 들어갈 자리를 만들고, 우측에 값을 튜플형태로 넣는다.
a = 0b1011011
b = 0xc5f
print('이진수 : %d, 십육진수: %d' % (a,b))
이러한 %-formatting 방식이 있고, 또 str.format()메서드 방식이 있는데 주로 python 2 에서 사용해왔다고 한다.
이러한 표기법에는 몇 가지 문제가 있다.
1번째 문제점은 형식화 식에서 오른쪽에 있는 tuple 내 데이터 값의 순서를 바꾸거나 값의 타입을 바꾸면 타입 변호나이 불가능하므로 오류가 발생할 수 있다.
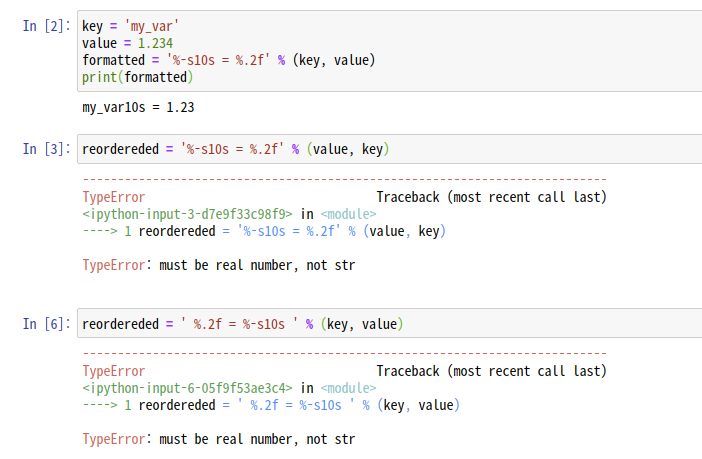
2번째 문제점은 '가독성'이다.
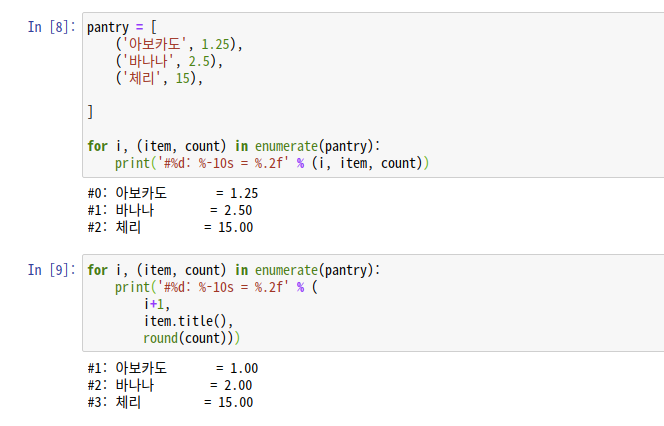
위 코드에서 값을 변경해야 할 경우 tuple의 길이가 길어져서 가독성이 떨어진다.
딕셔너리에 있는 키는 형식 지정자에 있는 키(%(key)s)와 매치된다.
아래 예제는 이 기능을 사용해 출력에 아무런 영향을 주지 않으면서 형식화 식의 오른쪽에 있는 값의 순서를 바꿨다.
key = 'my_var'
value = 1.234
old_way = '%-10s = %.2f' % (key,value)
new_way = '%(key)-10s = %(value).2f' % {
'key': key, 'value': value # 원래 방식
}
reordered = '%(key)-10s = %(value).2f' % {
'value': value, 'key': key # 바꾼 방식
}
assert old_way == new_way == reordered
print(old_way)
print(new_way)
print(reordered)
형식 연산자 우측에 key 와 value 라고 해서 딕셔너리에 있는 값들이 들어갈 자리를 만들어줬다. 튜플형식에서 사용하는 것과 동일하다. 이러한 문제점은 중복이 되게끔 코드를 입력할 때 가독성이 떨어진다는 동일한 문제를 야기한다.
f-string 등판
정리하자면, '가독성'이 떨어지는 코드가 나오므로 기존의 방식들은 좋지 못했다.
이러한 문제를 해결하기 위해 파이썬 3.6 부터는 인터폴레이션을 통한 형식 문자열(f-string) 이 도입됐다.
이번 포스팅에서는 이 부분에 대한 설명이 목적이다.
key = 'my_var'
value = 1.234
formatted = f'{key} = {value}'
print(formatted)formatted = f'{key!r:<10} = {value:.2f}'
print(formatted)
f-string 은 가독성과 중복성에 대한 문제를 모두 해결해준다.
s1 = 'left'
result1 = f'|{s1:<10}|'
print(result1)
# f-string 가운데 정렬
s2 = 'mid'
result2 = f'|{s2:^10}|'
print(result2)
# f-string 오른쪽 정렬
s3 = 'right'
result3 = f'|{s3:>10}|'
print(result3)
위 코드에서 보이듯이 중괄호 {}안에 있는 변수 뒤에 콜론(:)을 붙인 후 왼쪽 정렬 (<), 오른쪽 정렬(>), 가운데 정렬(^)의 옵션을 넣어줍니다. 그 후에 자릿수를 알려주는 숫자 를 넣어주면 정렬 옵션을 사용할 수 있습니다.
f_string = f'{key:<10} = {value:.2f}'
c_tuple = '%-10s = %.2f' % (key,value)
str_args = '{:<10} = {:.2f}'.format(key,value)
str_kw = '{key:<10} = {value:.2f}'.format(key=key, value=value)
c_dict = '%(key)-10s = %(value).2f' % {'key': key, 'value': value}
assert c_tuple == c_dict == f_string
assert str_args == str_kw == f_string
print(c_tuple)
print(c_dict)
print(f_string)
print(str_args)
print(str_kw)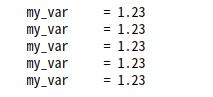
위 코드에서 c_tuple 과 c_dict 라고 이름 붙인 문자열 포매팅 방식은 C언어를 참고하였기에 네이밍된 것입니다.
위 코드에서 f-string 방식으로 하면 좀 더 간결해짐을 알 수 있습니다.
for i,(item, count) in enumerate(pantry):
old_style = '#%d: %-10s = %d' % (
i+1,
item.title(),
round(count))
new_style = '#{}: {:<10s} = {}'.format(
i+1,
item.title(),
round(count))
f_string = f'#{i+1}: {item.title():<10s} = {round(count)}'
assert old_style == new_style == f_string
print(old_style, '\n', new_style, '\n', f_string)
위 코드에서 가독성이 어떻게 나아지는지 느끼실 수 있다고 생각합니다.
3가지 형식의 문자 포매팅 방식 중 무엇이 더 낫다고 느껴지시나요?
제가 참고한 서적과 포스팅을 천천히 읽어본다면 f-string이 왜 더나은지 좀 더 알 수 있을 거라고 생각합니다.
앞으로 문자열 포매팅을할 때는 무조건 f-string을 통해서 만들려는 습관을 가지면 좋을 것 같습니다.
사용할 때 기억해야 할 점은 f 와 {} 2가지 이고, 문자열 맨 앞에 f 를 붙이고, 중괄호에 직접 변수 이름이나 출력할 표현식을 넣어주시면 됩니다.
f'문자열 {변수} 문자열'
입니다.
# 참고
www.python.org/dev/peps/pep-0498/
파이썬 코딩의 기술(개정2판)
www.yes24.com/Product/Goods/94197582
'Python_programming > 초중급편' 카테고리의 다른 글
| python if not , isinstnce (330) | 2020.12.13 |
|---|---|
| python 범위 규칙, 할당, assignment, UnboundLocalError: local variable referenced before assignment (4) | 2020.12.12 |
| 파이썬 이터레이터(iterator)와 이터러블(iterable) 차이점 (0) | 2020.04.20 |
| 파이썬 함수 코드 스타일 PEP20 - 1 (0) | 2020.04.16 |
| 파이썬 객체 내부 검사 - dir, type, id, __dict__ ,네임 스페이스 (0) | 2020.01.11 |



